1 Introduction
This document specifies semantics and syntax constraints for tables. Tables reference subsets of the facts and fact related information defined by a DTS, and specify representation of those facts in a Cartesian coordinate system. A table defines a virtual space which represents an arrangement of facts. Applications may display facts from an existing instance according to this arrangement, or allow entry of new facts according to this arrangement.
All tables defined by this specification can be used for rendering existing instances, and some may be used for the addition or modification of facts to form new instances. This specification does not constrain the details of how these facts are presented or entered.
This specification defines the semantics of the table linkbase. It also describes a syntax that is used to represent these semantics.
Tables use hierarchies to specify the arrangement of XBRL facts. These hierarchies are one of the basic building blocks of the specification, but also constitute by themselves a vehicle to communicate the meaning of those reporting concepts in a similar fashion to that of the presentation linkbase, but enhanced to cover multidimensional information and more complex models.
This specification defines the semantics of tables (and the syntax to define them). It does NOT define how tables should be rendered or formatted. References to specific formatting decisions are provided for explanation purposes only, and tools are free to produce any rendering that honours the logical structure of the table(s).
1.1 Relationship to other work
This specification depends upon the XBRL Specification [XBRL 2.1], the XBRL Dimensions Specification [DIMENSIONS] and the XBRL Formula Specification [FORMULA].
1.2 Namespaces and namespace prefixes
Namespace prefixes [XML NAMES] will be used
for elements and attributes in
the form ns:name where ns is the
namespace prefix and name is the local name.
Throughout this specification, the mappings
from namespace prefixes to actual namespaces are consistent
with Table 1.
The prefix column in Table 1 is non normative. The namespace URI column is normative.
| Prefix | Namespace URI |
|---|---|
table |
http://xbrl.org/2014/table |
xbrlte |
http://xbrl.org/2014/table/error |
tablemodel |
http://xbrl.org/2014/table/model |
eg |
http://example.com/ |
link |
http://www.xbrl.org/2003/linkbase |
xbrli |
http://www.xbrl.org/2003/instance |
xfi |
http://www.xbrl.org/2008/function/instance |
xbrldi |
http://xbrl.org/2006/xbrldi |
xbrldt |
http://xbrl.org/2005/xbrldt |
xl |
http://www.xbrl.org/2003/XLink |
xlink |
http://www.w3.org/1999/xlink |
xs |
http://www.w3.org/2001/XMLSchema |
xsi |
http://www.w3.org/2001/XMLSchema-instance |
gen |
http://xbrl.org/2008/generic |
gpl |
http://xbrl.org/2013/preferred-label |
variable |
http://xbrl.org/2008/variable |
formula |
http://xbrl.org/2008/formula |
tuple |
http://xbrl.org/2010/formula/tuple |
df |
http://xbrl.org/2008/filter/dimension |
1.3 Document conventions (non-normative)
Documentation conventions follow those set out in the XBRL Variables Specification [VARIABLES].
1.4 XPath usage
XPath usage is identical to that in the XBRL Variables Specification [VARIABLES], except that the context item is undefined unless otherwise stated.
Such XPath expressions allowed by this specification are evaluated with no context item to avoid the use of arbitrary XPath expressions which rely heavily on the XML of the instance.
2 Uses
This specification defines two significant categories of use:
Data entry is the use of this specification for the purpose of entering new facts or editing existing facts in a (possibly new) instance document.
Data presentation is the use this specification for the purpose of rendering instance data.
Uses that fall outside these definitions are also acceptable.
3 Fact source
A fact source is a container for XBRL facts.
For example, a fact source may be an existing XBRL instance or may consist of new facts created (possibly on-demand) from information entered by the user.
The fact source consists of facts that are to be considered for inclusion in the table. The facts actually included in a table are those facts in the fact source that are in the domain of the table.
A fact source need not have a serialisation. It MAY exist only in memory, or be dynamically created on demand. A fact source MAY be modifiable.
4 Models
Three models are defined by this specification:
- The structural model represents the structure of each table, independent of the way it was defined and any details pertaining only to the way it will be rendered. It captures the meaning of the tables.
- The definition model defines the structural model using resources and relationships in the DTS. It is transformed into the structural model through the process of resolution.
- The layout model describes how the tables should be laid out.
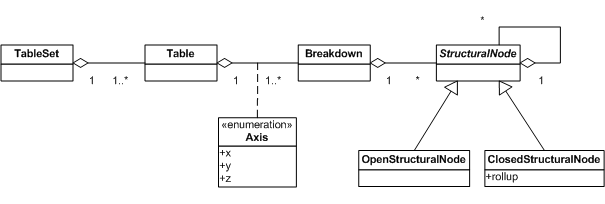
5 Structural model
The structural model describes a collection of one or more tables defined in a single linkbase, in a way that is independent of the way they were defined.
Tables are grouped into table sets.
The shape of each table is described in terms of hierarchical breakdowns of fact space.
Figure 1 shows the classes that participate in the structural model.
5.1 Tables
A table represents a breakdown of XBRL fact space for the purpose of defining a reference view of XBRL data.
A table consists of one or more independent breakdowns of the fact space. Together, these constrain the facts to be included in the table and describe their arrangement in the layout table.
The set of participating aspects for a table is the union of the participating aspects of each of the table's breakdowns.
The domain of a table is the restricted fact space defined by the combination of constraints from all of the table's breakdowns, along with any additional global constraints specified using table filters.
The domain of a table determines which facts are eligible for inclusion in the table.
The shape of the table is the particular arrangement of constraints into the breakdown trees for the table.
Tables may have a fixed shape, independent of the facts in the fact source. Alternatively, regions of a table may have shapes that vary depending on the facts in the fact source.
A closed table is defined as a table that consists only of closed breakdowns.
An open table is defined as a table whose constituent breakdowns include at least one open breakdown.
Each axis consists of a sequence of slices, where a single slice represents a position along that axis. A slice along the x-axis is a column. A slice along the y-axis is a row.
Any axis without any breakdowns has a single slice (e.g. a row or column) along that axis, which contributes no constraints. For example, a table with a single breakdown on the x-axis and no breakdowns on the y-axis will have one row, and a table with a single breakdown on the y-axis and no breakdowns on the x-axis will have one column.
5.2 Table sets
A table set is a set of one or more tables that share a common definition, parameterised by table parameters.
A single table definition is parameterised by its table parameters and produces a single table set that contains a sequence of tables.
A table set corresponds to an ordered Cartesian product of the sequences obtained by evaluating the global parameters associated with the table definition's parameters.
Each item in the ordered Cartesian product represents a set of bindings which bind each table parameter to a single value from the sequence obtained by evaluating the corresponding global parameter. Each of these sets of bindings corresponds to a table.
The ordering of this Cartesian product is derived from the order of the table-parameter relationships and the order of the global parameter evaluated sequences. The Cartesian product is ordered first according to the order of the first sequence then by each of the subsequent sequences in turn.
A table definition model resolves to a sequence of tables in a single table set in the structural model. The tables in a table set vary according to the values assigned to the table parameters.
5.3 Table parameters
A table parameter is a named parameter which binds to an item of the sequence obtained by evaluating a global parameter.
A table parameter is specified by a parameter declaration that is linked to a table through a table-parameter relationship.
For a given table in the structural model, each table parameter binds to an item in the sequence resulting from the evaluation of the global parameter. The value of the table parameter is assigned to a named variable. These variables may be referenced anywhere that the table linkbase syntax allows an XPath expression.
Table parameters allow multiple related tables to be produced from a single table definition, forming a table set.
5.3.1 Table-parameter relationships
A table-parameter relationship is a relationship
which:
<gen:link> <table:tableParameterArc> http://xbrl.org/arcrole/2014/table-parameter
A table-parameter-relationship MUST have a table:table resource on its "from" side.
Error code xbrlte:tableParameterSourceError
MUST be reported if the processing software
encounters a table-parameter relationship that does not have a
<table:table> resource
on its "from" side.
A table-parameter-relationship MUST have a parameter declaration on its "to" side.
Error code xbrlte:tableParameterTargetError MUST be reported if the processing software encounters a table-parameter relationship that does not have a parameter declaration on its "to" side.
The @name attribute on a table-parameter relationship
defines the QName of a variable bound to the value of the
table parameter for
the current table. Within the scope of a single table in a
table set, XPath variable
references with this QName evaluate to the value of the table parameter for that
table.
If this QName is the same as the QName given in the parameter declaration, XPath variable references with this QName are references to the variable containing the individual parameter value, which overrides the parameter reference.
The value of the @name attribute on a table-parameter
relationship MUST be unique within the scope of
a single table.
Error code xbrlte:tableParameterNameClash
MUST be reported if the processing software
encounters a table-parameter relationship with a value for the
@name attribute which is the same as the value of the
@name attribute on any other table-parameter relationship
for the same table.
5.4 Breakdowns
A breakdown defines a logically distinct breakdown of the fact space by sets of constraints.
A breakdown is modelled as an ordered tree of structural nodes. Each of these nodes contributes zero or more constraints to the breakdown.
These constraints are grouped into one or more constraint sets, which may each be associated with a tag. There may be at most one constraint set without a tag for a given node. Each type of node in this specification defines the constraint set(s) it contributes.
A node which does not explicitly define any constraint sets is deemed to have a single empty constraint set.
Different constraint sets for the same node MUST NOT have the same tag.
Error code xbrlte:duplicateTag MUST be reported if the processing software encounters a tag which is used on more than one constraint set for the same node.
All constraint sets for the same node MUST consist of constraints for exactly the same aspects.
Error code xbrlte:constraintSetAspectMismatch
MUST be reported by the
processing software for each aspect A and each constraint set S such
that S does not constrain A, but there exists another distinct set T
for the same node which does constrain A.
Each node may have a number of tag selectors which specify the tags to be selected when determining the combined constraints for a cell as described in Section 7.6.
Each leaf node corresponds to a row (or column) in the table and each
path through the breakdown tree from root to leaf determines the
constraints to be satisfied by
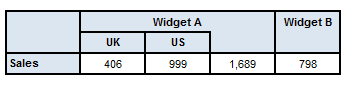
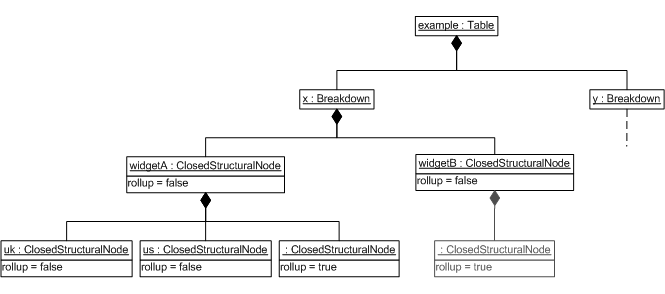
facts in the corresponding row (or column). Figure 2illustrates a simple table, in
which sales figures (y-axis) are broken down by two
dimensions: Product and Geography
(x-axis). Figure 3
shows (part of) the corresponding structural model (the constraints
associated with each node are not shown).
5.4.1 Breakdown labels
A breakdown may have associated labels. Each of these labels applies to the breakdown as a whole.
5.4.2 Uniform depth
All leaf nodes in a breakdown are at the same level in the tree. A path from the root node to any leaf node will therefore have the same length.
A tree that has this property is referred to as a uniform depth tree. The process of height-balancing ensures that every breakdown consists of a uniform depth tree of nodes.
For example, in Figure 3 an
additional roll-up node is needed as a child of
widgetB. This additional node explicitly indicates
that the facts in the corresponding column are not further broken
down at the next level.
5.4.3 Constraints
A constraint is a restriction on the facts eligible for inclusion in a table cell, in terms of their aspect values.
A fact satisfies a constraint if the aspect value specified by the constraint is equal to the value of the same aspect for the fact.
Facts must satisfy all of the combined constraints of the intersecting rows and columns to be rendered or entered in a cell according to the rules laid out in Section 7.6.
Each constraint may be tagged to indicate that it only applies in combination with the corresponding tag selector.
Closed nodes have constraints which restrict an aspect to exactly one aspect value. For example, a closed node may restrict the "Geography" dimension to a single country. There are constructs in the definition model that allow many closed nodes to be defined using a single definition node. For example, it is possible to define a tree of closed nodes, each restricting the "concept" aspect to a different concept, by reference to a presentation network.
Open nodes have constraints which identify a single aspect to be constrained, but the aspect values are not known until layout is performed, and these may be dependent on the facts present.
The aspect values associated with closed definition nodes can be determined during the resolution process.
The aspect values associated with open definition nodes cannot be determined until expansion occurs as part of the layout process.
5.4.4 QName equality
Two QNames are QName equal if and only if their namespace URIs are equal and their local parts are equal.
5.4.5 Aspect value equality
Two aspect values are aspect value equal if they are values for the same aspect and are also equal according to the rules specified for that aspect.
Two aspect values for the concept aspect are equal if the QNames of the concepts they identify are equal.
Two aspect values for the period aspect are equal if the period values are equal as defined in XBRL 2.1.
Two aspect values for the unit aspect are equal if the unit values are equal as defined in XBRL 2.1.
Two aspect values for the entity identifier aspect are equal if the entity identifier values are equal as defined in XBRL 2.1.
Two aspect values for the same explicit dimension aspect are equal if the the QNames of the members they identify are equal.
Two aspect values for the same typed dimension aspect are equal if they have corresponding typed dimension values. Note that custom typed-dimension aspect tests are not used by this specification.
Two aspect values for the non-XDT segment aspect are equal if the
xfi:nodes-correspond XPath function would deem them to be. The
aspect value for the non-XDT segment aspect is the (potentially empty)
ordered sequence of child elements of the segment element which do not
report values for XBRL dimensions. The analogous equivalence and
definition hold for the non-XDT scenario aspect.
5.4.6 Participating aspects
An aspect which is identified by a structural node is a participating aspect.
The participating aspects of a breakdown are the participating aspects of the structural nodes in the breakdown.
The aspects participating in a breakdown can always be determined during the resolution process, which does not require an instance.
5.4.7 Restrictions on aspect constraints
The aspect model of the table is the dimensional aspect model .
A table MUST NOT contain more than one breakdown that addresses the same aspect.
Error code xbrlte:aspectClashBetweenBreakdowns MUST be reported if the processing software encounters two or more breakdowns in a table that address the same aspect.
Each leaf node in a breakdown MUST have an associated aspect value per constraint set for all aspects in that breakdown. For a given aspect, the leaf node itself or one of its ancestors may explicitly define a value for that aspect. Where neither the leaf node itself nor any ancestor explicitly specifies an aspect value for some aspect participating elsewhere in the same breakdown, the following rules apply:
- For explicit and typed dimensional aspects, the absence of a reported value for that dimension is inferred. For explicit dimensions with a default, this is equivalent to constraining to that default.
- For non-dimensional aspects, the absence of such a constraint is an error.
For example, the two nodes in Figure 3 with
rollup=true constrain the
Geography dimension to its default value.
Error code xbrlte:missingAspectValue MUST be reported if the processing software encounters a leaf node in a breakdown which does not specify or inherit a value for any non-dimensional aspect which participates elsewhere in that breakdown.
5.4.8 Combining breakdowns
Breakdowns are combined by taking the Cartesian product of the individual lists of constraints.
For a single breakdown in isolation, the leaf nodes of the breakdown tree each correspond to a single slice (e.g. a row or column) in the layout table. Branch nodes correspond to headers in the layout table that span the headers corresponding to the descendant nodes.
Every breakdown is associated with one of the axes defined by the layout model. Several breakdowns may be projected onto a single axis in the layout table, as described in Section 9.3.2. Interactive tools MAY provide a mechanism to allow the user to pivot the table by moving breakdowns between axes and re-ordering breakdowns on the same axis.
5.4.9 Closed breakdowns
A closed breakdown is defined as a breakdown whose sequence of constraint sets can be determined independently of the facts to be included.
A closed breakdown cannot directly depend on an instance. However, a closed breakdown may depend on parameters. An application can always provide values for these parameters to satisfy this dependency. The expression for the default value for such a parameter may refer to the content of the instance document, and an application can evaluate this expression against the fact source if it is an instance document.
5.4.10 Open breakdowns
An open breakdown is defined as a breakdown whose sequence of constraint sets changes dynamically with the facts included and thus cannot be completely determined without knowledge of those facts.
An example of an open breakdown is one that breaks down facts by period. For presentation of existing data, this requires a slice (e.g. row or column) for each period against which a fact is reported. For data entry, it requires the ability to dynamically create and populate new slices as the user enters data.
A tool that supports data entry into open tables SHOULD provide a method for the user to create new rows or columns in dynamic regions of the table and to specify the necessary aspect values.
5.5 Structural nodes
A structural node is a node in a breakdown tree. Each node contributes zero or more constraints to the breakdown.
A structural node may contribute no constraints, in which case it exists solely to group together its children (possibly contributing a header to the table axes; see Section 5.5.4).
Structural nodes can be classified into two groups: open structural nodes and closed structural nodes.
5.5.1 Closed structural nodes
A closed structural node is a structural node with constraints fully determined by its definition and the DTS.
A closed structural node does not depend on the facts in the instance to determine its constraints.
A closed structural node has been fully resolved during resolution, and is not further expanded during layout.
A breakdown that consists only of closed structural nodes is, by definition, a closed breakdown.
Closed structural nodes can be roll-up nodes.
5.5.2 Open structural nodes
An open structural node is a structural node that does not fully define aspect value constraints and does not necessarily have a one-to-one relationship with layout nodes produced during resolution.
An open structural node has exactly one participating aspect.
During resolution, an open structural node is expanded to a number of layout nodes.
The ordering of layout nodes produced during this expansion is implementation-defined.
An open structural node semantically represents a set of values for a given aspect. For example, an open structural node may represent "all periods used in the fact source". For data presentation, the contexts are required in order to enumerate the periods which will ultimately determine the number of slices (e.g. rows or columns). For data entry, the open node acts as a placeholder for the periods period entered into the application. The application MAY expand this placeholder according to the values already entered and MAY display a placeholder directly, possibly using it to accept new data.
A breakdown that contains at least one open structural node is, by definition, an open breakdown.
5.5.3 Roll-up nodes
A roll-up node is a closed structural node which represents an aggregation of its siblings.
A roll-up node contributes no additional constraints to a breakdown. It is always the first or last child of its parent, but is not otherwise different from its non-roll-up equivalent.
A processor MAY choose to merge the header cell corresponding to a roll-up node with its parent when rendering the table.
5.5.4 Structural node labels
A closed structural node may be associated with one or more labels, as described in Section 6.10, for the purpose of labelling the header cells it contributes to the layout table. Every header cell corresponding to a given structural node shares the same labels. Open structural nodes do not have labels. The labelling of header cells is described in Section 7.4.
For any node which has no labels, processors are free to choose labels corresponding to that node's constraints. For a node with a single concept or explicit dimensional member that has not been inferred according to Section 5.4.7, processors SHOULD use one or more labels associated with the concept in the DTS. Processors SHOULD NOT add labels for any constraints inferred according to Section 5.4.7.
Any labels which are not explicitly attached to a definition node, which are attached to a structural node by a processor MUST be indicated as coming from the processor. In the layout model serialisation, the "processor" value for the @source attribute is used.
It is desirable to allow the application to use existing labels corresponding to the node's constraints where possible. Where an appropriate label already exists in the DTS, an explicit label is NOT RECOMMENDED.
5.6 Path labels
The path label of a given resource role for a leaf node in a breakdown is the sequence of node labels of that same resource role associated with the nodes in the path from the root of the breakdown to the leaf.
5.7 Slice labels
The slice label of a given resource role for a slice (e.g. a row or column) is the sequence formed from the concatenation of the path labels of that same resource role for the slice.
The path labels for a slice are the path labels of the leaf node which aligns with the slice, in each of the breakdowns on the axis.
The order of the concatenation is the order defined by the breakdowns by the table linkbase.
If an application allows breakdowns to be reordered within an axis or pivoted between axes, it MUST use the original order and axis when determining slice labels.
5.8 Cell labels
The cell label of a given resource role for a cell is a map from each axis to the slice label of that same resource role for the slice which aligns with the cell on that axis.
5.9 Unspecified aspects
The concept aspect MUST participate in the table.
Error code xbrlte:tableMissingConceptAspect MUST be reported if the processing software encounters a table in which the concept aspect does not participate.
The absence of any other aspect has no effect on the structural model. See also Section 9.3.1.
6 Definition model
The definition model is a direct representation of the contents of a table linkbase. The syntax of the linkbase provides a direct description of the definition model.
A table linkbase MUST consist of one or more valid generic links. Violations of this requirement MUST be detected by validation against the Generic Links Specification [GENERIC LINKS] and the XBRL Specification [XBRL 2.1].
Figure 4 illustrates the definition model.
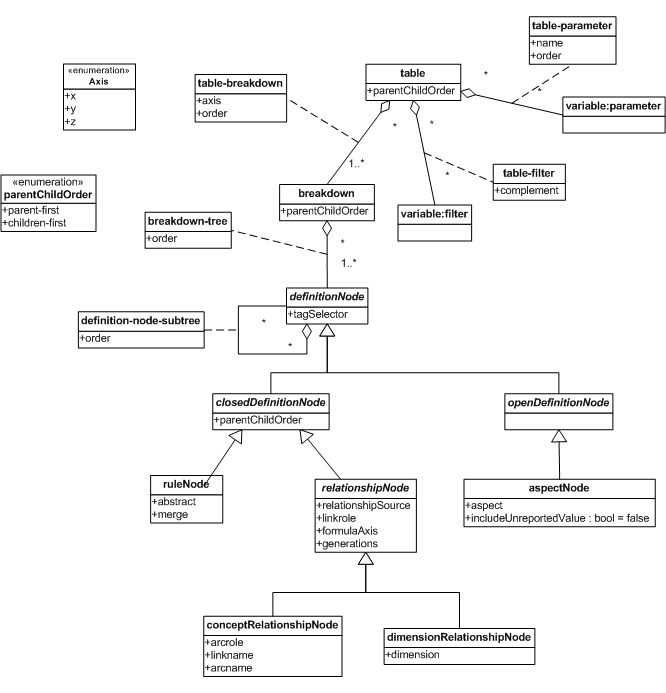
6.1 Tables
A table is defined by a <table:table> resource with at least one
table-breakdown
relationship. A <table:table> without any such relationships has
no meaning within the scope of this specification.
The <table:table> element
is related to breakdown
definitions which define the shape of the table. It can
also be related to filters which restrict the domain of the table.
The @parentChildOrder attribute on a table declaration
defines the default placement of roll-up nodes contributed by
all closed definition
nodes in the table for which it is not overridden, as
described in Section 6.5.3.1.
A single table definition potentially defines multiple tables in the structural model. All tables in the structural model resulting from a single definition are grouped into a table set.
6.1.1 Table labels
Tables MAY be associated with generic labels and generic references, as described in Section 6.10. These labels apply to every table in a table set.
6.2 Table filters
Tables may be associated with filters through table-filter relationships.
The context item for XPath expressions of table filters is each candidate fact being considered to meet the conditions that would make it an accepted member of the domain of the table.
6.2.1 Table-filter relationships
A table-filter relationship is a relationship
which:
<gen:link> <table:tableFilterArc> http://xbrl.org/arcrole/2014/table-filter
A table-filter-relationship MUST have a table:table resource on its "from" side.
Error code xbrlte:tableFilterSourceError
MUST be reported if the processing software
encounters a table-filter relationship that does not have a
<table:table> resource
on its "from" side.
A table-filter-relationship MUST have a filter on its "to" side.
Error code xbrlte:tableFilterTargetError MUST be reported if the processing software encounters a table-filter relationship that does not have a filter on its "to" side.
The @complement attribute on a table-filter relationship
indicates whether the filter's effect is inverted. The default
value is @complement=false. A table-filter
where the @complement attribute has a value of
true uses the filter complement
rather than the filter itself.
6.4 Breakdowns
Breakdown definitions define breakdowns using trees of definition nodes. Breakdown definitions may also have generic labels. These label the breakdown as a whole.
A breakdown definition
is represented by a <table:breakdown> resource.
The <table:breakdown>
resource is related to trees of definition nodes which define the
shape of the breakdown.
The @parentChildOrder attribute on a breakdown
defines the default placement of
roll-up nodes contributed by all closed definition nodes
in the breakdown (as described in Section 6.5.3.1) and overrides the value inherited
from the table.
6.4.1 Table-breakdown relationships
A table-breakdown relationship is a relationship
which:
<gen:link> <table:tableBreakdownArc> http://xbrl.org/arcrole/2014/table-breakdown
A table-breakdown-relationship MUST have a table:table resource on its "from" side.
Error code xbrlte:tableBreakdownSourceError
MUST be reported if the processing software
encounters a table-breakdown relationship that does not have a
<table:table> resource
on its "from" side.
A table-breakdown-relationship
MUST have a <table:breakdown> resource
on its "to" side.
Error code xbrlte:tableBreakdownTargetError
MUST be reported if the processing software
encounters a table-breakdown relationship that does not have a
<table:breakdown>
resource on its "to" side.
The ordering of breakdowns
is the order of the table-breakdown relationships, as defined by
their order
attributes. Where no order attribute is specified on a
relationship, or if two relationships have identical order
attributes, the relative ordering is implementation-defined.
However, it MUST be deterministic. Ordering of
breakdowns is only significant for relationships that have the
same value for their @axis attribute.
6.4.2 Breakdown labels
Breakdowns MAY be associated with generic labels and generic references, as described in Section 6.10. These labels provide an overall description of content of the breakdown.
6.5 Definition nodes
A definition node is a definition of zero or more structural nodes in the structural model.
Definition nodes are represented by elements in the substitution
group for the abstract <table:definitionNode> element. The following
types of definition node
are defined by this specification:
This section specifies syntax and semantics common to all types of definition node.
Definition nodes contribute nodes to the structural model through the resolution process (described in Section 9.2). The specific contribution to the structural model depends on the type of definition node, and is described in the corresponding section for a given type of definition node.
Definition nodes and the structural nodes they contribute are classified as either "closed" or "open".
Definition nodes can include a tag
selector using the @tagSelector attribute.
Specific types of definition node define override the value of this
attribute (for example concept relationship nodes). Except where
this value is overriden, all structural nodes defined by a single
definition node share this tag selector value.
6.5.1 Extension
Definition nodes MAY be extended using qualified attributes in other namespaces. Any such attributes MUST NOT affect the meaning of anything defined by this specification.
6.5.2 Labelling
The following types of definition node MUST NOT have labels:
- Merged rule nodes
- Relationship nodes
- Aspect nodes
Error code xbrlte:invalidUseOfLabel MUST be reported if the processing software encounters a definition node of any of the above types which has one or more labels.
6.5.3 Closed definition node
A closed definition node is a definition node which resolves to one or more closed structural nodes .
The figure below provides a model of the closed definition nodes.
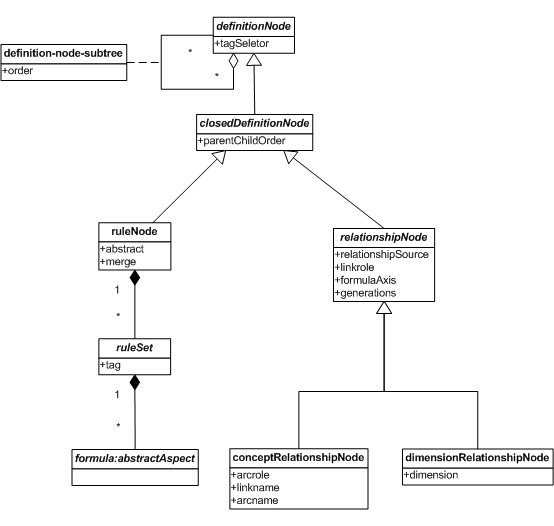
Closed definition nodes define trees of structural nodes.
There are three types of closed definition nodes defined by this specification:
Those which resolve to a single structural node, or
two structural nodes where one is a roll-up node and is a child of
the other. This type of definition node may have children. Given
such a definition node D which resolves to
structural node S (where S is either
the single contributed node, or the parent node if two nodes are
contributed), any of the top-level structural nodes contributed by
children of D are children of S.
Those which resolve to a tree of structural nodes and may depend on the DTS. For example, a single closed definition node may resolve to a tree of structural nodes representing a concept tree. This type of definition node cannot have children.
Those which exist to group other closed definition nodes and contain common properties to be contributed to their children.
A closed definition node which does not contribute common properties to its children MUST contribute at least one structural node to the table.
Error code xbrlte:closedDefinitionNodeZeroCardinality MUST be reported if the processing software encounters a closed definition node which does not contribute common properties to its children and does not contribute at least one structural node to the table.
A closed definition node is instance-independent, and can therefore be used to define a table which can be used for both data entry and data presentation.
6.5.3.1 Parent-child ordering
Wherever a definition node contributes a roll-up node, the position of
the roll-up node relative to its siblings is determined by the
effective value of the @parentChildOrder attribute on
the contributing definition node, which can take either of two
values:
parent-first: the roll-up node MUST be laid out as the first child of its parent node. This is the default value.children-first: the roll-up node MUST be laid out as the last child of its parent node.
The @parentChildOrder attribute may be specified on
a <table:table>
element, a <table:breakdown> element, or any element in
the <table:closedDefinitionNode> substitution
group.
The effective value of the @parentChildOrder attribute
on a closed
definition node is inherited by all children of that node that do not
explicitly specify a different value. Closed definition nodes
at the root of a breakdown definition
inherit the effective value of the @parentChildOrder
attribute of the <table:breakdown> element (which may in turn
have inherited it from the <table:table> element) as the default value of
their @parentChildOrder attribute.
6.5.4 Open definition node
An open definition node is a definition node which resolves to an open structural node.
A table with one or more open definition nodes defines an open table.
Aspect nodes are examples of open definition nodes.
6.5.5 Breakdown-tree relationships
A breakdown-tree relationship is a relationship
which:
<gen:link> <table:breakdownTreeArc> http://xbrl.org/arcrole/2014/breakdown-tree
A breakdown-tree-relationship MUST have a table:breakdown resource on its "from" side.
Error code xbrlte:breakdownTreeSourceError
MUST be reported if the processing software
encounters a breakdown-tree relationship that does not have a
<table:breakdown> resource
on its "from" side.
A breakdown-tree-relationship MUST have a definition node on its "to" side.
Error code xbrlte:breakdownTreeTargetError MUST be reported if the processing software encounters a breakdown-tree relationship that does not have a definition node on its "to" side.
A breakdown may be on the "from" side of more than one breakdown-tree relationship. The ordering of the individual breakdown trees is the order of the breakdown-tree relationships, as defined by their order attributes. Where no order attribute is specified on a relationship, or if two relationships have identical order attributes, the relative ordering is implementation-defined. However, it MUST be deterministic.
6.5.6 Definition-node-subtree relationships
A definition-node-subtree relationship is a relationship
which:
<gen:link> <table:definitionNodeSubtreeArc> http://xbrl.org/arcrole/2014/definition-node-subtree
A definition-node-subtree-relationship MUST have a resource derived from the table:definitionNode type on its "from" side.
Error code xbrlte:definitionNodeSubtreeSourceError MUST be reported if the processing software encounters a definition-node-subtree relationship that does not have a resource derived from the table:definitionNode type on its "from" side.
A definition-node-subtree-relationship MUST have a resource derived from the table:definitionNode type on its "to" side.
Error code xbrlte:definitionNodeSubtreeTargetError MUST be reported if the processing software encounters a definition-node-subtree relationship that does not have a resource derived from the table:definitionNode type on its "to" side.
The base set of a definition-node-subtree relationship MAY have undirected cycles but MUST NOT have directed cycles.
The children (singular: child)
of a definition node P are the targets
of
definition-node-subtree relationships whose source is
the definition
node P.
The ordering of the children is the order of the definition-node-subtree relationships, as defined by their order attributes.
The following types of definition node MUST NOT have subtrees:
Error code xbrlte:prohibitedDefinitionNodeSubtreeSourceError MUST be reported if the processing software encounters a definition-node-subtree relationship that has a prohibited definition node at its "from" end.
6.6 Rule node
This section specifies semantics and syntax constraints for rule nodes.
The figure below provides a model of the rule node.
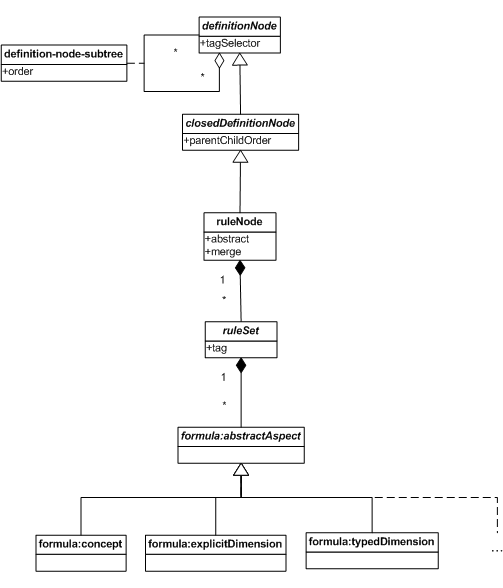
A rule node is a closed definition node that defines a structural node whose aspect constraints are defined by aspect rules. It may define an additional roll-up node which has no aspect constraints.
For example, a rule node may specify that a given slice (e.g. a row or column) should be constrained to facts reported against a certain period, or dimension member.
A rule node may be abstract, in which case it exists to group its children and contribute a parent structural node with a common set of constraints.
Alternatively, it may be non-abstract. In which case it also represents an aggregation of its children, and contributes a roll-up node with no constraints to the structural model.
For example, a non-abstract rule node whose children constrain facts to different members of an explicit dimension will typically have as its own constraint the default member of that dimension. In this case, the constraints specified by the children take precedence over that of the parent. The roll-up node has no constraint, and so the constraint specified by the parent applies.
A rule node may be merged in which case it contributes no structural nodes, but instead contributes its constraints to its children.
6.6.1 Rule node aspect rules
A rule node defines zero or more rule sets; sets of aspect rules. Each rule set MAY specify a tag. At most one of these rule sets may omit the tag.
Each rule set contributes a constraint set to the corresponding structural node during resolution. If there are no rule sets in the rule node, a single untagged empty constraint set is contributed.
The constraints of each constraint set are defined by the formula aspect rules.
The Formula specification defines aspect rules which specify output aspects.
This specification reuses this construct, but alters its interpretation in the following ways:
- The aspect values defined as the output aspects (required aspect values) by the Formula specification become the aspect values of the rule node's constraints.
- There is no source aspect value.
- The context item when evaluating any XPath expression is undefined.
Error code xbrlte:incompleteAspectRule MUST be reported if the processing software encounters an aspect rule that does not specify an aspect value.
Error code xbrlte:unrecognisedAspectRule MUST be reported if the processing software encounters an aspect rule for an aspect which is not part of the dimensional aspect model.
Within the scope of a single constraint set, there MUST NOT be more than one aspect rule for the same aspect.
Error code xbrlte:multipleValuesForAspect MUST be reported if the processing software encounters a constraint set which has more than one rule for the same aspect.
Aspect values that use a QName to identify an item declaration (e.g. a concept or dimension member) in the taxonomy MUST refer to an existing domain member declaration (as defined by the XBRL Dimensions 1.0 specification [DIMENSIONS]: an item declaration that is neither a dimension declaration nor a hypercube declaration). This requirement does not affect other aspect values, such as units, that involve QNames.
Error code xbrlte:invalidQNameAspectValue MUST be reported if the processing software encounters an aspect rule whose value does not refer to an existing domain member declaration.
6.6.2 Merged rule nodes
A merged rule node indicates additional properties which apply to all of its children. A merged rule node contributes no structural nodes directly, but instead contributes its constraints and its tag selectors to its children (which in turn will contribute structural nodes).
A merged rule node MUST NOT have any tagged rule sets. It contributes all of its constraints to every constraint set produced by its children.
Error code xbrlte:mergedRuleNodeWithTaggedRuleSet MUST be reported if the processing software encounters a merged rule node with a tagged rule set.
A merged rule node MUST NOT have any labels, as specified in Section 6.5.2.
A merged rule node MUST be abstract. Note that by virtue of the fact that all abstract nodes must have children, so must merged rule nodes.
Error code xbrlte:nonAbstractMergedRuleNode MUST be reported if the processing software encounters a non-abstract merged rule node.
6.6.3 Rule node syntax
A rule node is
represented by a <table:ruleNode> element with an optional
subtree of children.
The @abstract attribute on a <table:ruleNode>
element determines whether the node is abstract or not. This has
implications for how it
resolves (see Section 6.6.4). The default value is
@abstract=false.
An abstract rule node is a rule node that is
represented by a <table:ruleNode> element with
@abstract=true.
The @merge attribute on a <table:ruleNode>
element determines whether the node is merged or not. This has
implications for how it
resolves (see Section 6.6.4). The default value is
@merge=false.
A merged rule node is a rule node that is
represented by a <table:ruleNode> element with
@merge=true.
A <table:ruleNode>
element MAY have one or more elements from
the <formula:aspectRule> substitution group as
children of itself, or as children of <table:ruleSet> elements which are
children of itself. These are used to specify aspects and
aspect constraints for the node.
Each <table:ruleSet> element represents a rule set with the tag
specified by the @tag attribute. The children of the
<table:ruleSet> element specify constraints in the corresponding
constraint set with the same tag value.
The rules which are direct children of the ruleNode form the untagged rule set. These rules specify the constraints in the untagged constraint set.
If there is at least one tagged rule set, and no aspectRule children of the ruleNode, there is no untagged rule set.
If there are no tagged rule sets, and no aspectRule children of the ruleNode, the untagged rule set is empty.
The following <formula:aspectRule> features are NOT
processed: @source (all rules) and @augment
(unit rule).
A <table:ruleNode> MAY have
<formula:aspectRule> elements that have an
XPath expression.
The context item when evaluating any XPath expression in
such an aspect rule is undefined. XPath expressions
MAY refer to variables as described in
Section 6.9. XPath
expressions SHOULD be evaluated when
constructing the table, but are not expected to be
re-evaluated as data is entered (if used for data entry).
| Rule nodes | Explanation |
|---|---|
|
<table:ruleNode xlink:type="resource" xlink:label="parent" abstract="true"/>
<table:ruleNode xlink:type="resource" xlink:label="child1">
<formula:explicitDimension dimension="eg:Geography"> </table:ruleNode><formula:member> </formula:explicitDimension><formula:qname>eg:Europe</formula:qname> </formula:member><table:ruleNode xlink:type="resource" xlink:label="child2">
<formula:explicitDimension dimension="eg:Geography"> </table:ruleNode><formula:member> </formula:explicitDimension><formula:qname>eg:World</formula:qname> </formula:member><table:definitionNodeSubtreeArc xlink:type="arc" xlink:arcrole="http://xbrl.org/arcrole/2014/definition-node-subtree" xlink:from="parent" xlink:to="child1" order="1"/> <table:definitionNodeSubtreeArc xlink:type="arc" xlink:arcrole="http://xbrl.org/arcrole/2014/definition-node-subtree" xlink:from="parent" xlink:to="child2" order="2"/>
|
Defines two columns of a table. The parent rule node
is abstract and thus contributes no columns itself.
The two child nodes each define a single columns and
constrain the value of the |
|
<table:ruleNode xlink:type="resource" xlink:label="parent" parentChildOrder="children-first">
<formula:explicitDimension dimension="eg:Geography"> </table:ruleNode><formula:member> </formula:explicitDimension><formula:qname>eg:World</formula:qname> </formula:member><table:ruleNode xlink:type="resource" xlink:label="child">
<formula:explicitDimension dimension="eg:Geography"> </table:ruleNode><formula:member> </formula:explicitDimension><formula:qname>eg:Europe</formula:qname> </formula:member><table:definitionNodeSubtreeArc xlink:type="arc" xlink:arcrole="http://xbrl.org/arcrole/2014/definition-node-subtree" xlink:from="parent" xlink:to="child"/>
|
Defines two columns with identical constraints to the
previous example. The second column is a roll-up
contributed by the (non-abstract) parent rule node.
The parent node constrains the value of the
|
|
<table:ruleNode xlink:type="resource" xlink:label="parent" parentChildOrder="children-first">
<table:ruleSet tag="table.periodStart"> <formula:period> </table:ruleSet><formula:instant value="xs:date('2002-01-01')"/> </formula:period><table:ruleSet tag="table.periodEnd"> <formula:period> </table:ruleSet><formula:instant value="xs:date('2002-12-31')"/> </formula:period><formula:period> </table:ruleNode><formula:duration start="xs:date('2002-01-01')" end="xs:date('2002-12-31')"/> </formula:period> |
Defines a column with three alternative constraints for the period aspect. |
6.6.4 Rule node resolution
Each non-merged rule node resolves to either one or two structural nodes, as shown in Figure 7 and Figure 8, respectively.
Merged rule nodes do not resolve directly to any structural nodes, but instead contribute their constraints to their children.
A rule node, D, always contributes a single
structural node, S, as a child of the structural
node to which the parent of D resolves.
All children of D resolve to children of
S.
The constraints attached to the
structural
node S are those defined by the
aspect
rules attached to rule
node D.
If D is an abstract rule node, it resolves
to the single structural node,
S, as shown in Figure 7.
An abstract rule node MUST have at least one child.
Error code xbrlte:abstractRuleNodeNoChildren MUST be reported if the processing software encounters an abstract rule node with no children.
If D is a non-abstract rule node with at least
one child, it additionally contributes a single roll-up node, R,
as a child of S, as shown in Figure 8.
Placement of the roll-up
node is determined by the effective value of the
rule node's
@parentChildOrder attribute, as described in
Section 6.5.3.1. Figure 8 shows the
children-first case.

The roll-up node contributes no constraints, so the constraints of its ancestors apply.
6.6.5 Rule node labels
Rule nodes MAY be associated with generic labels and generic references, as described in Section 6.10.
During resolution, these labels are associated with the sole resulting structural node (if there is only one) or the parent structural node (if there are two).
A processor MAY add labels to the structural nodes contributed during resolution as described in Section 5.5.4.
6.7 Relationship nodes
This section specifies the semantics and syntax for relationship nodes. Relationship nodes provide an implementation of closed definition nodes that resolve into a tree of structural nodes, defined by networks of concepts or explicit dimension members in a DTS.
Figure 9 below provides a model of relationship nodes.
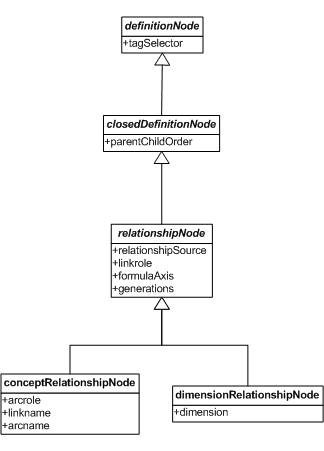
A relationship node is a closed definition node expressed in terms of networks of relationships between concepts. Here the term concept has the general meaning defined by the XBRL 2.1 specification [XBRL 2.1], not to be confused with the aspect of the same name.
A relationship node defines a tree walk of all or part of one or more networks of concepts.
The tree walk defined by a relationship node unambiguously identifies part of a network.
A relationship node resolves to an ordered tree of
structural nodes representing its tree walk. Each structural node
has a single untagged constraint set that constrains the relevant
aspect (the concept aspect in the case of a concept relationship
node or an explicit dimension aspect in the case of a
dimension relationship node) to a single value. The order of
sibling nodes is given by the order of the relationships by
which the concepts or dimension members associated with the nodes
were discovered. The ordering between a parent node and its
children is defined by the relationship node itself, and is
determined by the effective value of the
@parentChildOrder attribute, as described in
Section 6.5.3.1.
6.7.1 Relationship node syntax
Each concrete type of relationship node defines its own syntax and its own rules for traversing a tree of relationships. This specification defines two types of relationship node: the concept relationship node ( Section 6.7.4) and the dimension relationship node ( Section 6.7.5).
A relationship source identifies a starting concept for the tree walk.
All relationship nodes MUST identify at least one relationship source, either by providing syntax for the source to be explicitly specified by the table linkbase author or by defining a default relationship source in case it is not specified. Where more than one relationship source is specified, the order in which they are specified is significant and is reflected in the resulting tree of structural nodes. If a relationship source is duplicated then the same tree walk is performed once for each duplicate source.
Every relationship node MUST specify the
basic parameters of its tree
walk, consisting of values for the
formulaAxis and generations
properties.
The formulaAxis property is an enumeration whose
allowed values MUST be a subset of the
following set:
descendant, descendant-or-self,
child, child-or-self,
sibling, sibling-or-self,
sibling-or-descendant,
sibling-or-descendant-or-self. These values have
the same meanings as the corresponding values of the axis property
of concept relation filters [CONCEPT RELATION FILTERS] (with the addition of
sibling-or-descendant-or-self value, which behaves
like sibling-or-descendant but includes the
relationship source and its descendants). The token suffix
-or-self specifies that the relationship sources are
to be included. If the -or-self suffix is not present,
the top level rendered concepts are the children, parent or
siblings of the relationship sources.
Note that the value of the formulaAxis property only
affects which concepts are included in the tree walk. It has no effect on the
shape of the resulting tree of structural nodes. For example,
the siblings of a relationship source are always treated as
siblings, even if they are discovered by walking the network from
the relationship source.
The generations property is a non-negative integer
(xs:nonNegativeInteger) that limits the tree walk to the given number of
generations, in the same way as for concept relation filters
[CONCEPT RELATION FILTERS]. A value of
generations = 0 results in an unlimited
tree walk. The
relationship sources are not included when calculating the depth
of the tree walk, e.g. a
value of generations = 1 with
formulaAxis = descendant is equivalent
to specifying formulaAxis = child.
If the value of formulaAxis is child,
child-or-self, sibling or
sibling-or-self then the value of
generations MUST be either
0 or 1.
Error code xbrlte:relationshipNodeTooManyGenerations
MUST be reported if the processing software
encounters a value of formulaAxis that implies a
single generation tree walk in combination with a value of
generations greater than 1.
6.7.2 Relationship node expressions
Relationship nodes offer an alternative way to express some properties; using XPath expressions. The result of evaluating such an XPath expression MUST be castable to the data type of the equivalent non-expression element.
Error code xbrlte:expressionNotCastableToRequiredType MUST be raised if an XPath expression is encountered that is not castable to the required type.
XPath expressions used to specify the properties of a relationship node have no context item. They may, however, reference table parameters and global parameters defined in the DTS.
6.7.3 Relationship node labels
Relationship nodes MUST NOT have any labels, as specified in Section 6.5.2. During resolution, a processor SHOULD add labels as described in Section 7.4.
6.7.4 Concept relationship node
A concept relationship node is a relationship node which describes a tree of values for the concept aspect in terms of a tree walk of a network of concept-concept relationships.
Concept relationship nodes discover concepts by performing a tree walk of an XBRL 2.1 network. The tree walk is uniquely identified by the network and one or more relationship sources. A concept relationship node MUST identify a single network. In most cases, the combination of link role and arcrole is sufficient to unambiguously identify the network, but it may be necessary to specify additional information such as the arc name or the name of the extended link.
Error code xbrlte:ambiguousConceptNetwork MUST be reported if the processing software encounters a concept relationship node that provides insufficient information to unambiguously identify a single network.
It is not an error for a concept relationship node to specify properties for which there are no matching relationships in the DTS. In this case no relationships are found but the relationship sources themselves are still processed.
The participating aspect of a concept relationship node is the concept aspect.
As described in Section 6.5.6 concept relationship nodes cannot have subtrees.
6.7.4.1 Concept relationship node syntax
The syntax of concept relationship nodes is defined by the normative schema supplied with this specification.
A concept relationship node MAY include any
number of <table:relationshipSource> or
<table:relationshipSourceExpression> elements, each
containing, respectively, a QName (xs:QName) or an
XPath expression that evaluates to a QName identifying a single
relationship
source for the tree
walk. If a relationship source is specified, it
MUST be either:
- the QName of a concept that exists in the DTS, or
-
the special value
xfi:root.
Error code xbrlte:invalidConceptRelationshipSource
MUST be reported if the processing
software encounters a relationship source that is neither
the QName of a concept that exists in the DTS nor the
special value xfi:root.
The special value xfi:root represents a virtual
concept that has as its children the root concepts of the
specified network. When resolving a concept relationship node
with a relationship source of <xfi:root> , a table
linkbase processor MUST order the root
concepts of the network according to their QNames, as
described in Section 6.7.4.3
If no relationship
source is specified, the special value
xfi:root is assumed.
The <table:arcrole> or
<table:arcroleExpression> element is, respectively,
a non-empty URI (xl:nonEmptyURI) or an expression
that evaluates to a non-empty URI. In either case this URI
identifies the arcrole of the network(s).
The <table:linkrole> or
<table:linkroleExpression> element is, respectively,
a non-empty URI (xl:nonEmptyURI) or an expression
that evaluates to a non-empty URI. In either case, this URI
identifies the link role of the network(s). If no link role is
specified, the standard link role is used.
The <table:linkname> or
<table:linknameExpression> element is,
respectively, a QName (xs:QName) or an XPath
expression that evaluates to a QName. It identifies the name
of the extended link element defining the network(s).
The <table:arcname> or
<table:arcnameExpression> element is, respectively,
a QName (xs:QName) or an XPath expression that
evaluates to a QName. It identifies the name of the arcs
comprising the network(s).
The <table:linkname> and <table:arcname>
elements (and the corresponding expression-based equivalents)
are optional and need only be included if necessary to uniquely
identify the network.
If no relationships are found in the specified network, only the relationship sources are included in the resulting tree.
If the resulting tree is empty (for example, because the
relationship sources themselves are excluded by the choice of
formulaAxis) then this is an error, as described
in Section 6.5.3.
The <table:formulaAxis> or
<table:formulaAxisExpression> element, if present,
specifies the value of the formulaAxis property,
as defined in Section 6.7.1. If neither element is
present, the value descendant-or-self is assumed.
The behaviour of concept relationship nodes with each
combination of relationship source and
<table:formulaAxis> is described in Table 2 below.
formulaAxis |
relationshipSource |
Behaviour |
|---|---|---|
when the suffix -or-self is present
|
xfi:root |
The root relationships are equivalent to a virtual root source concept that has the root concepts of the network as children. |
| present |
The top level rendered relationship is a virtual
relationship that has as its child the named
relationship source. If the current binding is to a
source object, any @name variable does not
have a bound relationship object (it is an empty
sequence for the source objects).
|
|
when the suffix -or-self is not present
|
xfi:root |
The root relationships are the relationships whose source is a root concept of the network, causing the children of these root concepts to be the top level of rendered concepts. |
| present | The top level rendered relationships are the relationships that have as their parents the named relationship source, causing the children of the relationship source to be the top level of rendered relationships. |
The <table:generations> or
<table:generationsExpression> element is,
respectively, a non-negative integer or a non-negative integer
expression that, if present, specifies the value of the
generations property, which limits the tree walk
to the given number of generations, as described in
Section 6.7.1. If neither
element is present, a value of 0 is assumed.
6.7.4.2 Concept relationship node resolution
Each concept in the tree walk
resolves to at least one structural node, which both
constrains the value of the concept aspect to that
concept and acts as parent to structural nodes for each of that
concept's child concepts. Child structural nodes are ordered by
the @order attribute of the relationship linking the
child concept to its parent concept.
For concepts that are non-abstract and that are not leaves of the tree walk, an additional child roll-up node is added to reserve a position on the axis for facts reported against the concept. No roll-up node is added for abstract concepts or for concepts that have no child concepts.
Abstract concepts without any non-abstract descendants SHOULD be skipped. The resulting tree of structural nodes SHOULD NOT contain any leaf nodes with abstract concepts.
6.7.4.3 Ordering of network roots
Because the roots of a network have no incoming relationships
(other than the virtual relationships linking them to the
<xfi:root> virtual concept), their relative ordering
is undefined in [XBRL 2.1].
A concept relationship node may include the root concepts of a
network either because a relationship source of
<xfi:root> was specified, or because one of the
network roots was explicitly specified as a relationship
source, along with a value of sibling,
sibling-or-self, sibling-or-descendant or
sibling-or-descendant-or-self for the
formulaAxis property.
When resolving a concept relationship node that includes the root concepts of a network, a table linkbase processor MUST order them according to their QNames. QNames are ordered first by namespace then by local name, each using Unicode Codepoint Collation as used by [XPATH AND XQUERY FUNCTIONS].
6.7.4.4 Tag selection
If a preferred
label attribute is present on a relationship, this is
used to determine the tag selector value as described below.
A
preferred label attribute is either a
@preferredLabel attribute appearing on a
<link:presentationArc> element, or the
@gpl:preferredLabel appearing on any arc.
Error code
xbrlte:ambiguousPreferredLabel MUST
be reported if the processing software encounters a <link:presentationArc>
during the tree walk which has both the @preferredLabel and @gpl:preferredLabel
attributes.
- If the preferred label attribute value is
http://www.xbrl.org/2003/role/periodStartLabelthe tag selector value is table.periodStart. - If the preferred label attribute value is
http://www.xbrl.org/2003/role/periodEndLabelthe tag selector value is table.periodEnd. - Otherwise, the tag selector value of the concept relationship node itself is used.
Tag selectors MUST only be added for non-abstract concepts. That is:
- for non-abstract concepts at the leaves of the tree walk, the tag selectors are added to the corresponding structural node
- for non-abstract concepts elsewhere in the tree walk, the tag selectors are added to the roll-up nodes produced for these concepts
6.7.5 Dimension relationship node
A dimension relationship node is a relationship node which describes a tree of explicit dimension members in terms of a tree walk of a dimensional relationship set (DRS).
The tree walk of a dimension relationship node is uniquely identified by one or more relationship sources and the link role of the outgoing domain-member relationships. Dimension relationship nodes traverse the DRS by following consecutive relationships as defined by the XBRL Dimensions 1.0 Specification [DIMENSIONS].
The participating aspect of a dimension relationship node is a single explicit dimension aspect, referred to as the participating dimension.
As described in Section 6.5.6 dimension relationship nodes cannot have subtrees.
6.7.5.1 Dimension relationship node syntax
The syntax of dimension relationship nodes is defined by the normative schema supplied with this specification.
The participating
dimension of a dimension relationship node is
specified by a <table:dimension> element which contains
a QName (xs:QName). The QName MUST
identify an existing dimension
declaration in the DTS and the dimension
MUST be an explicit dimension.
Error code xbrlte:invalidExplicitDimensionQName MUST be reported if the processing software encounters a dimension relationship node that does not refer to an existing dimension declaration or that refers to a dimension declaration that is not an explicit dimension.
A dimension relationship node MAY include
any number of <table:relationshipSource> or
<table:relationshipSourceExpression> elements, each
containing, respectively, a QName (xs:QName) or
an XPath expression that evaluates to a QName identifying a
single relationship
source for the tree
walk. If a relationship source is specified, it
MUST identify an existing domain member
declaration.
Error code xbrlte:invalidDimensionRelationshipSource MUST be reported if the processing software encounters a relationship source that does not refer to an existing domain member declaration.
If no relationship source is specified, the root members of the domain of the participating dimension are used as the relationship sources. Specifically, the relationship sources are the targets of dimension-domain relationships with the specified link role whose source is the participating dimension. Note that the dimension-domain relationships may specify a target role that differs from the specified link role, so that the behaviour is potentially different from the case where the same relationship sources were specified explicitly. See Example 2 for example behaviour.
The <table:formulaAxis> or
<table:formulaAxisExpression> element, if present,
specifies the value of the formulaAxis property,
as defined in Section 6.7.1. For
dimension relationship nodes, valid values correspond to those
for explicit dimension filters [DIMENSION FILTERS]: descendant,
descendant-or-self, child or
child-or-self. If neither element is present, the
value descendant-or-self is assumed.
The behaviour of dimension relationship nodes with each
combination of relationship source and
<table:formulaAxis> is described in Table 3 below.
formulaAxis |
relationshipSource |
Behaviour |
|---|---|---|
when the suffix -or-self is present
|
omitted | The root relationships are the dimension-domain relationships that have the participating dimension as the source. |
| present |
The top level rendered relationship is a virtual
relationship that has as its child the named
relationship source. If the current binding is to a
source object, any @name variable does not
have a bound relationship object (it is an empty
sequence for the source objects).
|
|
when the suffix -or-self is not present
|
omitted | The root relationships are the relationships whose source is the target of a dimension-domain relationship which in turn has the participating dimension as its source, causing the children of these root members to be the top level of rendered members. |
| present | The top level rendered relationships are the relationships that have as their parents the named relationship source, causing the children of the relationship source to be the top level of rendered relationships. |
The <table:generations> or
<table:generationsExpression> element is,
respectively, a non-negative integer or a non-negative integer
expression (xs:nonNegativeInteger) that, if
present, specifies the value of the generations
property, which limits the tree walk to the given number of
generations, as described in Section 6.7.1. If neither element is
present, a value of 0 is assumed.
The <table:linkrole> or
<table:linkroleExpression> element is,
respectively, a non-empty URI or an expression
(xl:nonEmptyURI) that, if present, constrains
the network in which the node should begin traversing the DRS.
If no linkrole is specified then the standard link role is assumed.
If no relationships are found in the specified network then
no error is raised and the resulting tree comprises only the
relationship sources. However, if the relationship sources
themselves are excluded by the value of the
<table:formulaAxis> element then the resolved tree is
empty, which is an error, as described in Section 6.5.3.
| Dimension relationship nodes | Explanation |
|---|---|
|
<table:dimensionRelationshipNode xlink:type="resource" xlink:label="members">
<table:relationshipSource>eg:World</table:relationshipSource> <table:dimension>eg:Geography</table:dimension> <table:formulaAxis>descendant-or-self</table:formulaAxis> </table:dimensionRelationshipNode> |
Defines a tree of domain members for the explicit
dimension |
|
<table:dimensionRelationshipNode xlink:type="resource" xlink:label="members">
<table:dimension>eg:Geography</table:dimension> <table:formulaAxis>descendant-or-self</table:formulaAxis> </table:dimensionRelationshipNode> |
Defines a tree of domain members for the explicit
dimension
Assuming that |
|
<table:dimensionRelationshipNode xlink:type="resource" xlink:label="members">
<table:dimension>eg:Geography</table:dimension> <table:formulaAxis>child</table:formulaAxis> </table:dimensionRelationshipNode> |
Defines a tree of domain members for the explicit
dimension |
6.7.5.2 Dimension relationship node resolution
In general, each domain member in the tree walk resolves to at least one structural node. This node both constrains the value of the relevant dimension aspect to that member and acts as parent to structural nodes for each of that member's child members.
The Dimensions Specification [DIMENSIONS] allows certain members of the domain of an explicit dimension to be marked as unusable. Such members exist solely for the purpose of organising the domain into a hierarchy and are not expected to be used as actual values for the dimension. Processors SHOULD honour the usability of a domain member as defined by the incoming relationship. For usable members that are not leaves of the tree walk, an additional child roll-up node is added to reserve a position on the axis for facts reported with that dimension value. No roll-up node is added for unusable members or for members that are leaves of the tree walk.
Unusable members without any usable descendants SHOULD be skipped. The resulting tree of structural nodes SHOULD NOT contain any leaf nodes with unusable members.
Relationship sources that are specified explicitly are always
treated as usable, as there are no incoming relationships from
which to determine the usability. If the relationship source
is omitted then the usability of the domain roots is
determined from the incoming dimension-domain
relationships.
6.8 Aspect node
An aspect node is an open definition node which directly specifies a single participating aspect, and optionally a restriction on the facts used during expansion to determine the included values for that aspect.
The figure below provides a model of the aspect node.
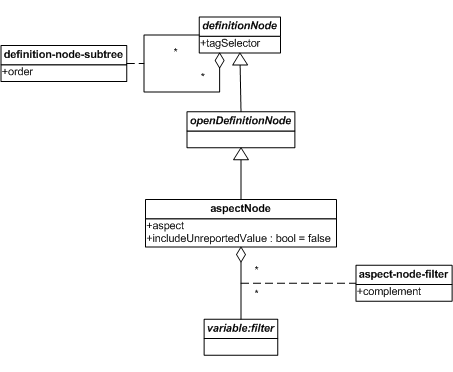
6.8.1 Aspect node aspect constraints
An aspect node has exactly one participating aspect, which is specified directly.
An aspect node contributes exactly one untagged constraint set.
Dimensional aspect specifications have an optional
@includeUnreportedValue property (which defaults to
false) which specifies whether the expansion should include a
"no value" placeholder when facts exist which have no value for
that aspect.
6.8.2 Expansion
During the expansion phase of the
layout process, an aspect node expands to one layout node for
each distinct value of its participating aspect present in its
set of contributing
facts, plus a single layout node representing the
absence of a reported value for the participating aspect if
@includeUnreportedValue is true and the
contributing
facts include at least one fact where no value is
reported for the participating aspect.
An aspect node can be associated with Formula filters to constrain the contributing facts used for this expansion.
The contributing facts for the aspect node are the facts in the fact source for the table, filtered according to the formula filters associated with the aspect node.
Note that the filters constrain the facts used to determine the aspect values which should be included during expansion, but they do not contribute any constraints to the table.
If the facts present in the fact source are as follows:
| Concept Aspect | Period Aspect | Fact Value |
|---|---|---|
| Profit | 2011 | 100 |
| Assets | 2012 | 100 |
| Profit | 2013 | 100 |
| Assets | 2013 | 200 |
Given the following definition of aspect node and associated filter:
The resulting table would look like this (assuming a suitable definition of the y-axis with concept as a participating aspect):
| 2013 | 2011 | |
|---|---|---|
| Profit | 100 | 100 |
| Assets | 100 | (unreported) |
The filter restricts the contributing facts to those with "profit" as the value for the concept aspect. The period aspect node then expands to a node for each value of the period aspect. There is no fact reported against the "profit" concept for the "2012" period, so only 2011 and 2013 are included. The constraints on the nodes on the x-axis only constrain the period aspect, so the values for the "assets" concept still appear in the final table.
This allows the y-axis to provide constraints for the concept aspect without causing an xbrlte:aspectClashBetweenBreakdowns.
6.8.3 Aspect node labels
Aspect nodes MUST NOT have any labels, as specified in Section 6.5.2. During expansion, a processor SHOULD add labels to the layout nodes as described in Section 7.4.
6.8.4 Aspect node syntax
An aspect node is represented by a <table:aspectNode>
element with exactly one child element in the
<table:aspectSpec> substitution group and optionally
one or more <variable:filter> resources related by
aspect-node-filter relationships.
The child element in the <table:aspectSpec>
substitution group specifies the participating aspect
of the aspect node.
The <table:conceptAspect> ,
<table:entityIdentifierAspect> , <table:periodAspect> ,
<table:unitAspect> elements specify the concept,
entityIdentifier, period and unit aspects respectively.
The <table:dimensionAspect> element specifies a dimensional
aspect by the dimension's QName. This MUST
be the QName of a dimension that exists in the DTS. It has an
optional @includeUnreportedValue attribute (which
defaults to false) which specifies the includeUnreportedValue
property of the aspect node.
Error code xbrlte:invalidDimensionQNameOnAspectNode MUST be reported if the processing software encounters a dimensionAspect element that specifies a QName which is not the QName of a dimension that exists in the DTS.
The context item for any XPath expression associated with an aspect node filter is the fact from the fact source being considered for inclusion as a contributing fact for the aspect node.
Filters MUST be evaluated when rendering an existing instance. An application supporting data entry MUST ensure that the facts entered into cells satisfy the associated filters but MAY defer this check until the instance is serialised.
The filters associated with a given cell are:
- the table filters for its table
- the filters attached to aspect nodes which expanded (see Section 6.8.2) into layout nodes which contribute constraints to the cell (see Section 7.6)
6.8.4.1 Aspect-node-filter relationships
An aspect-node-filter relationship is a relationship
which:
<gen:link> <table:aspectNodeFilterArc> http://xbrl.org/arcrole/2014/aspect-node-filter
A aspect-node-filter-relationship MUST have a table:aspectNode resource on its "from" side.
Error code xbrlte:aspectNodeFilterSourceError
MUST be reported if the processing software
encounters an aspect-node-filter relationship that does not have a
<table:aspectNode>
resource on its "from" side.
A aspect-node-filter-relationship MUST have a filter on its "to" side.
Error code xbrlte:aspectNodeFilterTargetError MUST be reported if the processing software encounters an aspect-node-filter relationship that does not have a filter on its "to" side.
A complemented aspect-node-filter relationship
is an aspect-node-filter relationship that is expressed by
a relationship with a @complement attribute that
has a value of true.
An aspect node with a complemented aspect-node-filter relationship to a filter uses the filter complement in its implied XPath expression.
6.9 Variable references
XPath expressions in definition nodes may refer to in-scope variables. These consist of the following types of variable:
- Global parameters defined anywhere in the DTS.
- Variables bound to the values of table parameters.
6.10 Labels
Elements in the definition model MAY be associated with generic labels or generic references for the purpose of labelling the corresponding parts of the rendered table.
Labels are associated with elements by XLink arcs which link the element to:
-
a
generic label, using the
http://xbrl.org/arcrole/2008/element-labelarcrole -
a generic reference, using
the
http://xbrl.org/arcrole/2008/element-referencearcrole
An element MAY be associated with any number of
generic labels and generic references. When more than one label or
reference is associated with an element, their order is given by
their effective relationships' XLink @order attribute. The
relative order of labels MUST be preserved in
the structural and
layout models.
7 Layout model
The layout model directly represents the layout and content of each table in a layout, where the content of a table includes both data, derived from XBRL facts, and header information documenting the meaning of that data.
The process of producing a layout from a structural model is described in Section 9.3.
7.1 Layout tables
A layout table represents an arrangement of selected XBRL facts following a matrix layout in a Cartesian space with x, y and z axes.
7.2 Axes
An axis defines an ordered mapping of XBRL fact space onto a line.
This specification describes three axes: x, y, and z. The following conventions for interpreting the different axes SHOULD be followed by rendering software where the output format allows it.
- The x-axis SHOULD be interpreted as a horizontal arrangement of columns in a table. Columns MAY be laid out from left to right, or right to left, according to the language conventions.
- The y-axis SHOULD be interpreted as a vertical progression of rows in a table. Rows SHOULD be laid out from top to bottom.
- The z-axis MAY be interpreted as multiple two-dimensional tables and MAY be laid out on a two-dimensional display by presenting each table in series or by supplying controls for the user to select the data to be presented.
Each position along an axis, corresponding to a slice (e.g. a row or column) in the table, is associated with a set of constraints on the fact space. An axis may be composed of multiple independent breakdowns of the fact space. These are combined by projecting them onto the axis, as described in Section 9.3.2.
Each one of the possible combinations of constraints along a table's axes, corresponding to a single cell in a table, is referred to as a coordinate.
7.3 Axis headers
Axis headers describe axes to communicate heading information about the cells at the intersections of rows and columns and to impart semantic structure to the table.
An axis may be associated with several rows (or columns) of headers, indicating multiple sets of nested constraints on the values displayed in the columns (or rows) of the table.
Each breakdown contributes a group of rows (or columns) of the header. Each group is associated with the labels associated with the corresponding breakdown.
Column (or row) spanning of individual cells SHOULD be used to indicate nesting of constraints, where the output format allows it.
Axis headers MAY be simplified when tables are rendered on media not meant primarily for human readability (such as CSV files, which lack a way to span or merge headers).
7.4 Header cell labels
For a header cell which has one or more labels associated with it (during resolution from the structural model), the processor MUST select one or more of these labels for rendering the header cell.
For a header cell which has no labels:
- If it has a single concept constraint or explicit dimension constraint, the processor SHOULD select a single label associated with that concept in the DTS.
- If it has a single unit, entity-identifier, period or typed dimension constraint, the processor SHOULD use a text representation of the constraint's aspect value.
The number of labels associated with a header cell has no impact on the logical structure of the layout model. A processor MAY render multiple labels for the same header cell as if they were distinct cells.
Header cells which are at the same logical level SHOULD be aligned when rendering.
When choosing a single label, the generic label with the standard
resource role (http://www.xbrl.org/2008/role/label), if
available, SHOULD be used in preference to other
labels.
If multiple labels for the same header cell are rendered, the @order attribute MUST be honoured.
7.5 Cells
Cells are located at the intersections of rows and columns and act as containers for XBRL facts.
Each cell contains the facts (if any) that satisfy all of the constraints associated with the particular row and column at whose intersection they are located, as well as any global constraints associated with the table.
A cell may contain zero or more facts. If more than one fact is associated with a cell then the behaviour is implementation-defined. A tool MAY choose to display all or a subset of the values. Alternatively, a tool MAY display a visual indication that the cell contains multiple values.
In tools that support data entry, a cell may be editable, to allow a user to enter new facts or to edit existing facts. This specification places no restrictions on how tools present this editing functionality to users.
7.6 Cell constraints
The constraints which apply to a given cell are determined as follows:
- The set of constraint-contributing nodes is the set of nodes which align with the cell.
- The tag selector set for the cell is the union of the tag selectors for each of these nodes.
- Exactly one constraint set from each of these nodes is chosen.
- For a given node, if a single constraint set is present which is tagged with any of the tag selectors , it is chosen.
-
For a given node, if multiple constraint sets are present
which are tagged
with any of the
tag selectors, it is an error.
Error code xbrlte:tagSelectorClash MUST be reported if the processing software encounters a cell that has aligned nodes with more than one tag selector which match constraint sets of an aligned node for that cell. - For a given node with an untagged constraint set, if no constraint sets are present which are tagged with any of the tag selectors, the untagged constraint set is chosen.
-
For a given node without an untagged constraint set, if no
constraint sets are present which are tagged with any of the
tag selectors, it
is an error.
Error code xbrlte:noMatchingConstraintSet MUST be reported if the processing software encounters a cell that has an aligned nodes with no matching constraint set.
- Where different aspect values for the same aspect are present in this set, only the aspect value from the node closest to the leaf is used.
The constraints according to the above rules are the combined constraints for the cell. A fact should be included in the cell if and only if all of these combined constraints are satisfied.
8 Serialisation
This specification defines a canonical XML serialisation of the layout model. The syntax is defined by the normative schema supplied with this specification (see A.2).
For most of the XML elements in the schema, ordering is significant and corresponds to the order in which the corresponding cells in the table are laid out, as outlined below.
The layout model serialisation is used by the conformance suite to compare layouts produced by tools implementing this specification to those expected from a conformant processor.
8.1 Table sets
Each table set is
represented by a <tablemodel:tableSet> element, as a child of the
root <tablemodel:tableModel> element. A serialised layout model may contain any number
of table sets.
A table set may be
optionally associated with a list of labels, which apply to all the
tables in the set (these are the labels attached to the original
table in the definition model). These are represented by zero or
more <tablemodel:label>
elements. The order of the labels is given by the relationships
linking them to the original table in the definition model.
Each table set must have at least one child
<tablemodel:table> element.
8.2 Tables
A table is represented by a
<tablemodel:table> element.
A <tablemodel:table> element must have as its children:
-
exactly one
<tablemodel:cells>element describing the contents of the table cells -
one or more
<tablemodel:headers>elements describing the headers for each axis of the table.
8.3 Axis headers
The headers for an axis are declared by a <tablemodel:headers> element.
The required attribute @axis indicates which of the
three defined axes a <tablemodel:headers> element is associated with.
Valid values of this attribute are x, y and
z. Only one <tablemodel:headers> element may be associated
with each axis for a given table.
Individual headers for an axis are represented by <tablemodel:header>
elements, one header for each one for each row (or column) of header
cells for a single axis. These are nested inside a <tablemodel:group>
element which contains the header elements based on the breakdown they
were contributed by. These group and header elements are ordered
starting from the outside of the table (i.e. farthest from the data
cells) and working inwards. Each <tablemodel:group>
element contains a sequence of zero or more <tablemodel:label>
elements corresponding to the labels for the breakdown that group is
representing, followed by a sequence of zero or more <tablemodel:header>
elements.
A <tablemodel:header> element contains a sequence
of <tablemodel:cell> elements.
Each <tablemodel:cell> element contains a sequence
of <tablemodel:label> elements and a sequence of
<tablemodel:constraint> elements.
Each <tablemodel:constraint>
element describes a constraint as an aspect-value pair.
Each <tablemodel:label>
element describes the label associated with a single header cell.
These are ordered according to the natural direction of ordering in
the rendered table.
The @source attribute on the label element indicates
where the label originated. If the label was not associated
explicitly with a definition node, this attribute
MUST be provided with a value other than
"explicit".
Spanning of multiple rows or columns in the table is indicated in
the document by an optional @span attribute on the
<tablemodel:cell> element. The value of this attribute is a positive integer
giving the number of table columns spanned by the header cell. If
the attribute is not specified then a span of 1 is assumed. The
total number of columns spanned by all the labels on each header row
for a given axis should be the same.
Roll-up nodes are indicated by an optional @rollup
attribute with a value of true.
8.4 Table cells
Each cell is represented by a single <tablemodel:cell>
element.
The <tablemodel:cell> elements are arranged into
nested <tablemodel:cells> elements.
Each <tablemodel:cells> represents a dimensional slice
of the data. The number of dimensions involved in the slice depends
on the level of nesting.
A series of <tablemodel:cell>
elements is contained in a <tablemodel:cells>
element, which represents a one dimensional sequence of cells along
a single axis, indicated by the @axis attribute on the
containing <tablemodel:cells>
element. The position of each cell along the indicated axis is
determined by its position within the containing <tablemodel:cells>
element.
The most nested <tablemodel:cells>
elements may each be contained in another <tablemodel:cells>
element, which represents a two dimensional slice of cells along
another axis. These in turn may be nested inside a single <tablemodel:cells>
element, representing a three dimensional slice (of which there is
only one).
In this way, each level of nesting addresses a more specific part
of the data. The position of a child element C within
a <tablemodel:cells>
element P with an @axis attribute
value of A determines the position along axis
A of all cells which are descendants of C
(or C itself).
A <tablemodel:cells> element contains either a
sequence of <tablemodel:cell> elements, or a sequence of
nested <tablemodel:cells> elements. Each <tablemodel:cells>
element must specify (using the required @axis
attribute) the axis along which its contained slices or cells are
arranged.
The value of the @axis attribute on a <tablemodel:cells>
element must be one of the three axes defined by this
specification: x, y and z. All
sibling elements must have the same value for the
@axis attribute. Elements must never have the same
value of the @axis attribute as one of their
ancestors.
The content of a <tablemodel:cell>
element describes the content of a single data cell. It consists of
a sequence of zero or more
<tablemodel:fact>
elements. Each of these contains the URI of a fact which is in the cell.
The URI will consist of an instance document location with an
XPointer to the fact within the document.
A <tablemodel:cells> element may only be empty if it is the outermost
(and only) element for the enclosing table. This indicates that the table contains
no cells. Otherwise, it MUST contain either a child <tablemodel:cells>
element or a non-empty sequence of <tablemodel:cell> elements. Note also
that the nesting of <tablemodel:cells> elements is restricted to defining
the axes in a fixed order (z, y, x).
9 Processing model
9.1 Compilation
Compilation is the process of parsing the table linkbase and producing a definition model.
9.2 Resolution
Resolution is the process of building a structural model from the definition model.
The resolution process has the DTS available, but not a fact source (for example, an instance), so that it produces a structural model that is useful both for data entry and data presentation.
9.2.1 Table set resolution
A single table definition can define multiple tables in a table set in the structural model, according to the values its parameters can take, as described in Section 5.3.
Implementations MAY provide a series of values for each parameter to produce multiple tables (the table set), or they MAY provide a single value for each parameter to produce a single table (this may be seen as "selecting" a table from the table set).
Given a single value for each parameter, a single table in the structural model is produced by resolving the table definition. Resolution of a table definition to a table set for a series of values for its parameters is equivalent to sequentially resolving against a single set of parameter values, for each set of parameter values in the series.
9.2.2 Table resolution
The general process of resolving a table definition to a table structure is described here. The individual descriptions of definition node types describe how they contribute to the structural model.
Each breakdown in the definition model is resolved to a breakdown in the structural model by following the resolution rules for each node in the breakdown definition.
The resulting tree of structural nodes is based on the tree of definition nodes. Each node in the definition model resolves to one structural node, a tree of structural nodes or a list of structural nodes.
9.2.3 Definition node resolution
For a definition node D that resolves into a single
structural node S or a structural node S
with a child roll-up node
R:
-
The parent of
Sis the structural node to which the parent ofDresolves. -
The children of
Sare the roll-upRand the resolved children ofD.
For a definition node D that resolves to a tree of
structural nodes, with structural node S being the root
of this tree:
-
The parent of
Sis the structural node to which the parent ofDresolves. IfDhas no parent,Shas no parent. - The non-root structural nodes in the result are arranged as described in the specification of the definition node.
For a definition node D that exists to group other
definition nodes and contribute common properties to its children:
-
The parent of the resolved children
S1..Snis the structural node to which the parent ofDresolves. IfDhas no parentS1..Snhave no parent.
Despite representing a number of aspect values, and ultimately a number of columns or rows in the rendered output, open definition nodes resolve to one open structural node since they depend on a fact source (typically an instance). The resulting open structural node represents a part of the table which is dynamic.
9.2.4 Height balancing
Height-balancing is performed so that there is an unambiguous correspondence between nodes on the same level of the breakdown (and an unambiguous alignment of header cells in the final rendering).
This is particularly important when projecting multiple breakdowns onto an axis.
Height-balancing adds a single roll-up node at each level under any leaf nodes up to the required depth.
9.3 Layout
The layout process takes the structural model and a fact source and produces a layout.
The facts of a table are from the fact source which MAY be an XBRL instance (data presentation), or MAY be virtual allowing new facts created from information entered into a tool by a user to produce a new or edited output XBRL instance (data entry). In the latter case, the table provides a description of the facts that may be entered.
The layout process MAY be interactive. Examples of interactive layout include allowing the user of a tool to move breakdowns between axes or select the language in which axis headers and text-valued facts are displayed.
A layout is a result of the layout process.
9.3.1 Under-specified tables
9.3.1.1 Dimensional aspects
The non-participation of a dimensional aspect implicitly constrains the facts in the table to those which do have no aspect value for that aspect or have the default aspect value for that aspect.
For explicit dimensions with a default, this will have the effect of only including facts for the default member.
For explicit dimensions without a default, and for typed dimensions, this will have the effect of only including facts not reported against that dimension.
9.3.1.2 Non-dimensional aspects
The non-participation of non-dimensional aspects leaves the cells in the table to be unconstrained with respect to those aspects.
The handling of this case is implementation defined, and is described in Section 9.3.1.3
9.3.1.3 Multiple values in a cell
Multiple facts may match the constraints for a single cell. In this case, the behaviour is implementation defined. Applications MAY choose to handle this in one of the following ways:
- by displaying the most appropriate fact or facts. For example, locale may be used to select the fact with the most appropriate language or unit.
- by displaying a single fact, where the values are consistent,
- by producing separate instances of the table for each value of an unconstrained aspect. For example, if period is unspecified, it may be desirable to produce a rendered table for each period present in the instance.
- by providing user interface controls for the user to select which facts are displayed. For example, the user may be presented with a choice of entity identifiers present in the instance, and shown a table containing only the facts relating to the selected entity.
9.3.2 Projection of multiple breakdowns onto an axis
Multiple breakdowns may be associated with a single table axis. Breakdowns on an axis are ordered according to the
@order attributes of the table-breakdown
relationships linking their definitions to that of the
table.
Projection is the process of combining two or more independent breakdowns into a single effective breakdown for display on a single axis.
Any additional constraints inferred under Section 5.4.7 are added to the relevant individual breakdown before projection.
The effective breakdown for a single breakdown is the breakdown itself.
The effective breakdown for a pair of breakdowns is the tree formed by attaching an identical copy of the second breakdown to each leaf of the first breakdown, such that the root nodes of the second breakdown become the children of the leaves of the first breakdown, as illustrated in Figure 11.
The effective
breakdown for an ordered set of n individual
breakdowns is the effective
breakdown for the following pair of breakdowns:
- the effective breakdown for the first
n-1individual breakdowns - the last individual breakdown
The effective breakdown for an axis is the result of projecting all of the individual breakdowns associated with that axis.
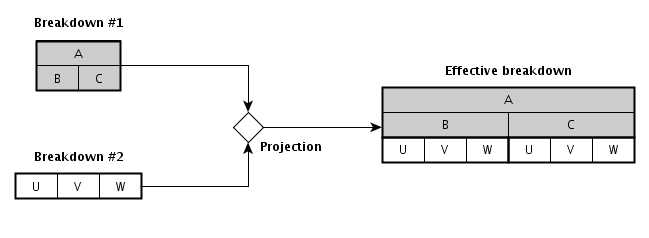
The projection in
Figure 12 involves a more
complex breakdown, that includes two roll-ups (B
requires padding with an additional roll-up node to bring the first
breakdown tree to a uniform
depth (see Section 5.4), thus ensuring that the
individual breakdowns line up correctly in the effective breakdown.
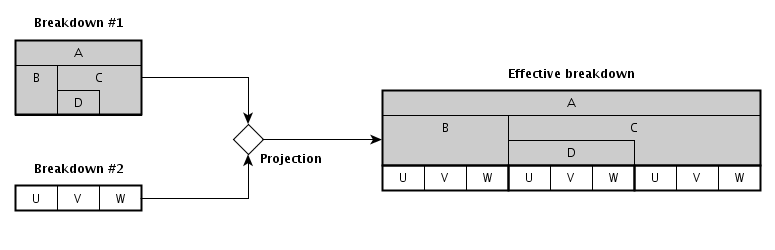
9.3.3 Headers
As part of the layout process, headers are constructed for each axis of the table. Axis headers are produced after projecting the breakdowns in the structural model onto axes, as described in Section 9.3.2.
Axis headers are
constructed from nodes in the structural model. Each
breakdown contributes a
number of rows/columns of header cells to the header for the axis with which it is associated. Each
level of a breakdown tree
contributes a single row/column of header cells to the header, with each structural node contributing
zero or more header cells. Header rows are ordered first by the defined
order of the breakdowns
(initially given by the @order attribute of the table-breakdown
relationships) and then by depth within each breakdown tree.
9.3.4 Elimination
Elimination is the process of eliminating unpopulated slices (e.g. rows and columns) to produce a more compact table.
An unpopulated slice is a slice of a table is one whose constraints match no facts when populating the table.
When laying out a table for data presentation:
- Processors MUST be able to produce a complete table in which no slices have been eliminated.
- Processors MAY eliminate some or all unpopulated slices.
The conformance suite for this specification expects output tables to have no slices eliminated.
Processors MUST NOT perform elimination when laying out a table for data entry.
9.3.5 Expansion
Expansion is the process of expanding an open structural node during the layout process.
This expansion depends on the fact source.
Aspects that participate in expansion are referred to as expansion aspects.
An open structural node contributes one layout node for each value of each expansion aspect it defines. Every open definition node defines the expansion aspects of its corresponding structural node.
- See Section 6.8.2 for a description of expansion for aspect nodes (the only open nodes defined by this specification).
9.3.6 Layout for data presentation
Given a set of facts from the fact source, the layout process MUST constrain these facts to those which satisfy all table filters (if any) associated with the table.
These facts MUST be arranged in the table according to the constraints associated with its slices (e.g. the columns, rows and positions along the z-axis).
9.3.7 Layout for data entry
Closed tables have a fixed shape in that they do not depend on facts in a fact source, so the initial layout process for data entry is the same as for data presentation of an empty fact source when performing no elimination.
Open tables have a shape that depends on the fact source. For data entry, the facts in the fact source can change (and it will often be empty initially).
Processing software that supports data entry MUST allow the user to dynamically add aspect values for any expansion aspects. These aspect values MUST be validated against the constraints defined by the open definition nodes.
For example, if an open definition node defines period as an expansion aspect, but defines no constraint, the user should be able to create new columns for any period. If an open definition node defines a typed dimension as a expansion aspect, constraining values to a be numeric, the user should be able to create new columns for that dimension and the user should either be prevented from entering non-numeric values or any non-numeric value entered should cause a validation error after entry.