
A Getting Started Guide: Experimenting with LLMs for XBRL Analysis
The exciting potential of using Large Language Models (LLMs) to analyse financial data, especially structured data like XBRL reports, is becoming increasingly apparent. Imagine asking an LLM to summarise key financial insights directly from an XBRL document – this is the kind of experiment many are eager to begin.
However, those embarking on this venture quickly encounter a hurdle. XBRL reports in their traditional formats like Inline XBRL (iXBRL) and xBRL-XML, while digitally tagged and structured, present complexities when fed directly into LLMs. Their XML-based structure is not inherently intuitive for these models, since it requires specific parsing and understanding of XBRL taxonomies. Many aspiring experimenters find themselves stuck at this initial data-ingestion stage, struggling to make sense of raw XBRL data within the LLM environment.
This is where xBRL-JSON comes into play. xBRL-JSON is part of a family of newer report formats, and a wide range of tools are now available that can convert from one XBRL format into another. Designed with easier consumption by tools and systems in mind, xBRL-JSON offers a vastly simpler and more intuitive representation of XBRL data. Its structure is inherently more ‘LLM-friendly,’ facilitating smoother data ingestion and analysis. xBRL-JSON bridges the gap, making precise XBRL data readily accessible for freeform experimentation within LLMs.
This blog post is for anyone curious about experimenting with XBRL reports and exploring the capabilities of LLMs like ChatGPT. Whether you are a financial analyst, data scientist, or simply an XBRL enthusiast, this guide will provide a practical starting point for your journey.
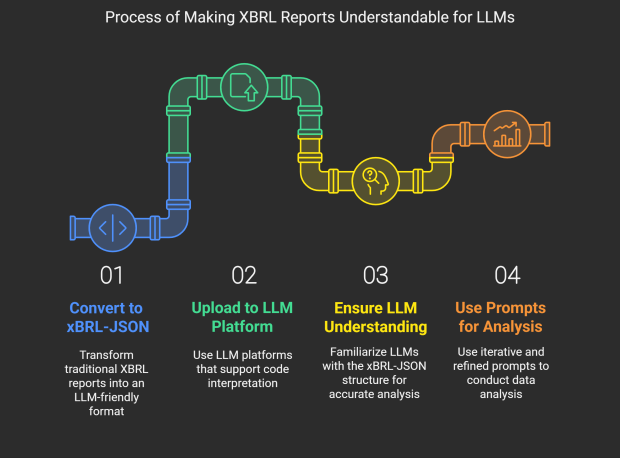
Step 1: Conversion to xBRL-JSON Format
We begin by addressing the central challenge: making XBRL reports readily understandable for Large Language Models. This relies on transforming the more complex traditional XBRL formats – whether iXBRL or xBRL-XML – into the streamlined xBRL-JSON format. The formats are designed for lossless transformation, meaning that no data is lost or misinterpreted during this conversion process.
You can use the XBRL Certified Software of your choice for conversion (providing it is certified for the xBRL-JSON module). For this post, I utilised the Arelle GUI, a user-friendly interface for the open-source Arelle XBRL platform. The conversion process is very simple: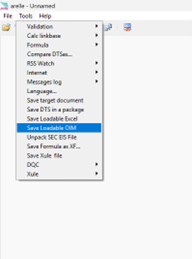
- Open Your XBRL Report: Launch Arelle and open your source XBRL report file (either iXBRL or XBRL-XML format) within the application. Ensure that the saveLoadableOIM plugin is enabled. You can manage plug-ins from the ‘Help’ menu by selecting ‘Manage plug-ins’.”
- Save as xBRL-JSON: Navigate to the “Tools” menu, select “Save Loadable OIM” and choose “Save as type” – “JSON file.json”. Select a destination to save your converted file.
- Conversion Complete! In just a few clicks, you’ve successfully transformed your XBRL report into xBRL-JSON. You now have an LLM-friendly version of your XBRL data, ready for exploration.
For those who prefer automation or command-line operations, here is the documentation for command-line usage for xBRL-JSON report conversion in Arelle.
filings.xbrl.org is a repository of Inline XBRL filings hosted by XBRL International. For each filing the tagged data is also available as an xBRL-JSON report. These can be used directly for LLM experiments.
Step 2: Uploading xBRL-JSON to in LLM
Now that we have our xBRL-JSON report, the exciting part begins: exploring it with an LLM!
In this example, we’ll use Google Gemini to interact with our newly converted xBRL-JSON data. Please note that for analysing xBRL-JSON reports, you need to use large language models with integrated code interpreters. At the time of writing these include ChatGPT, Gemini, and Mistral.
Let’s start by uploading the xBRL-JSON report file into Gemini. To upload a file, simply click on the “Upload” icon below the chat box and select your .json file. This works the same way in most LLM interfaces.
Step 3: Ensure LLM Understanding
A great first step in our exploration is to understand how well Gemini grasps the structure of this xBRL-JSON data. So, our initial query will be designed to probe this question, rather than the data itself. For instance, we can ask:
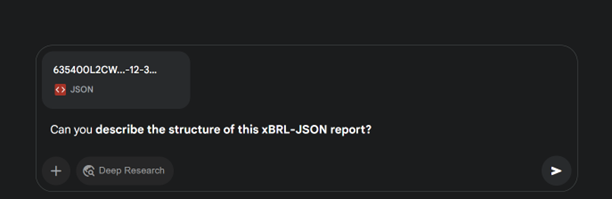
Gemini answered as follows:

Gemini appears to have correctly interpreted the data’s structure, which builds confidence for further analysis. When working with LLMs on data analysis, this initial step ensures that the model fully understands the data and its relationships.
While most leading LLMs like ChatGPT, Gemini, and Mistral generally understand the structure of well-formed xBRL-JSON files, it’s not guaranteed that the model will always interpret it correctly. If the model doesn’t seem to understand the structure or responds with errors or incomplete answers, don’t worry – you can guide it:
- Try explaining what the file contains, e.g., “This JSON file contains XBRL data with key financial facts under the ‘facts’ node.”
- Mention any important structure tips, like where to find entity names, period data, or units.
Helping LLMs with a sentence or two of orientation can make a big difference. You can also check if the LLM has understood the data correctly by asking simple test questions like “What is the entity name?” or “What period does this report cover?”
Step 4: Use Prompts for Analysis
We can now proceed to ask questions about the report we uploaded.
Simple queries
Here we make a simple query about reported profit growth using everyday language.
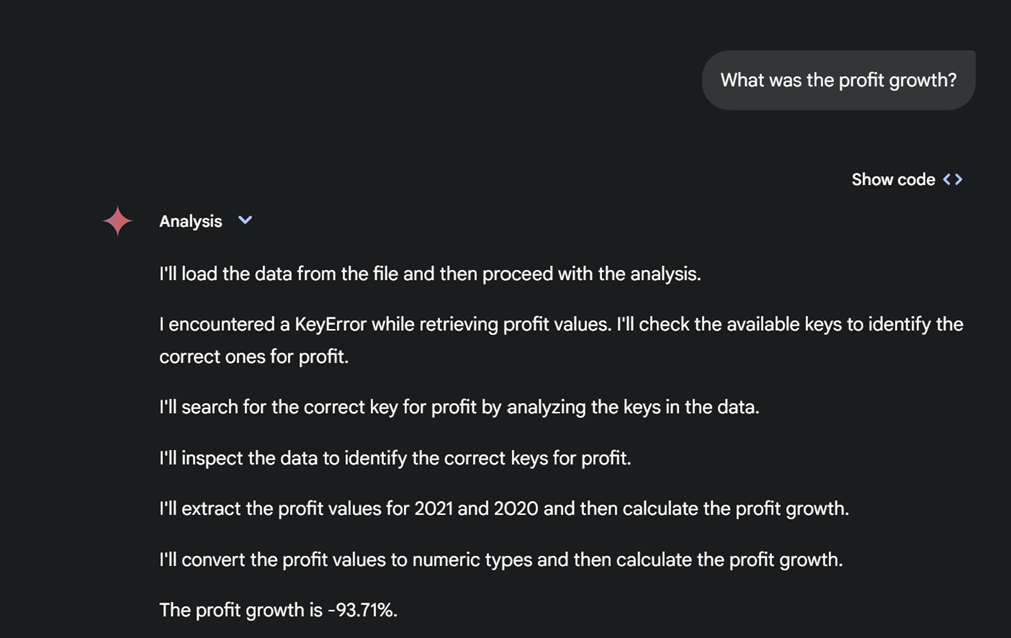
This looks correct, but let’s check which concept the model has used:
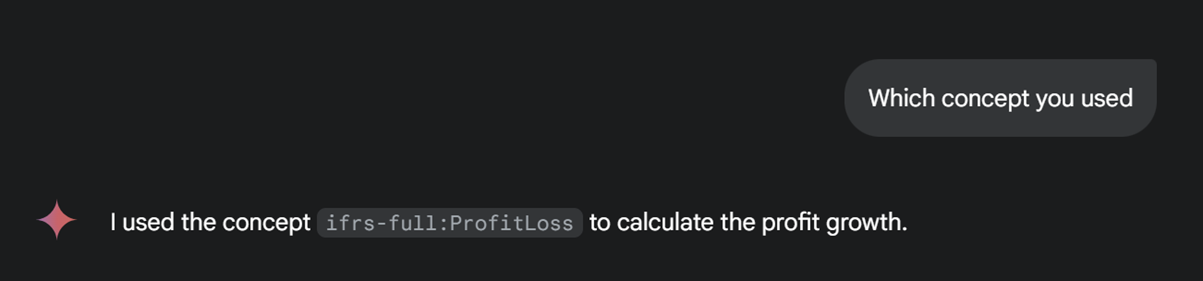
This gives us a deeper understanding of the judgment made by the LLM, showing that it selected the correct disclosures from the source report. The traceability and transparency provided by XBRL are crucial in providing verifiable, trustworthy insights.
Financial ratio calculations
Let’s calculate some financial ratios.
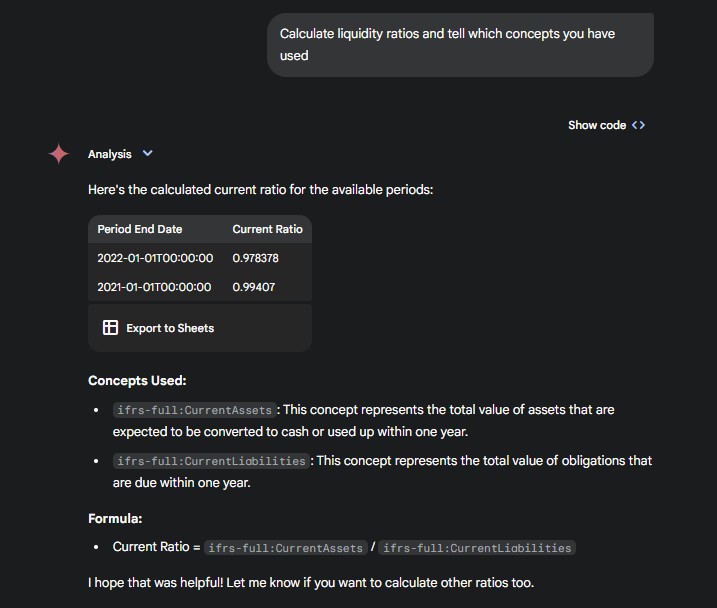
The answers are correct, and the information provided about the concepts used gives us a clear picture of how the calculations were made.
Narrative disclosure analysis
Here is an example of query asking an LLM to summarise a narrative disclosure. Here I uploaded a different report in ChatGPT.
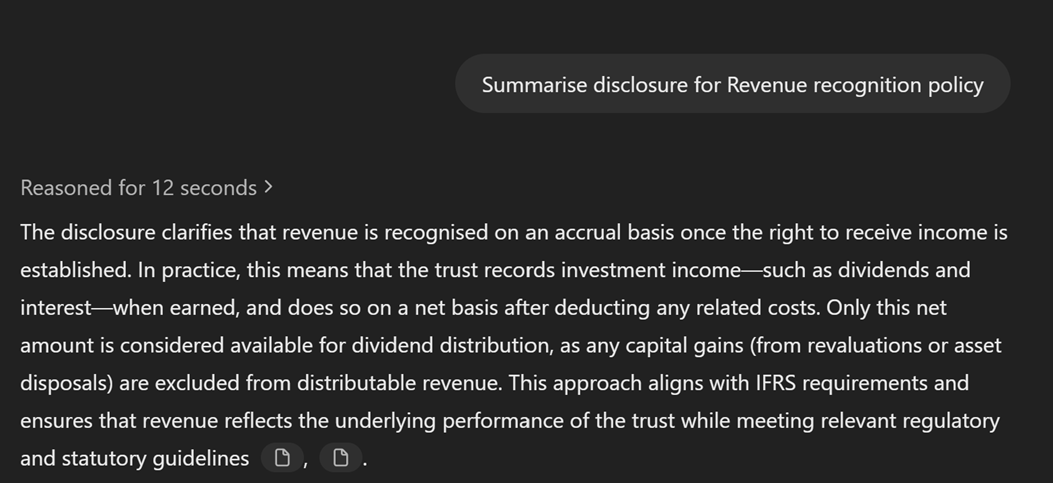
The answer provides an easily digestible summary of the accounting policy.
For more ideas about how to use LLMs to get to grips with narrative disclosures, I have explored various approaches in another post.
Analysis across different reports
You can upload multiple xBRL-JSON reports over a time period or from different companies and carry out a comparative analysis. To work with multiple reports in an LLM, just upload all the relevant .json files one after another. You can then refer to them by name when asking questions or making comparisons.
Here is an example of trend analysis across four consecutive annual reports from the same company:

This answer appears to offer a useful summary for understanding the key trends in this company’s revenue over recent years.
Reasoning Models
LLMs now automatically give their reasoning, providing clarity on their workings. AI is no longer a black box demanding unquestioning trust. Instead, it is possible to check how the LLM you are using has executed a query, ensuring confidence in your conclusions. Here is an extract from the reasoning for the above trend analysis query. The reasoning is typically provided as part of an LLM’s response, above the final answer.
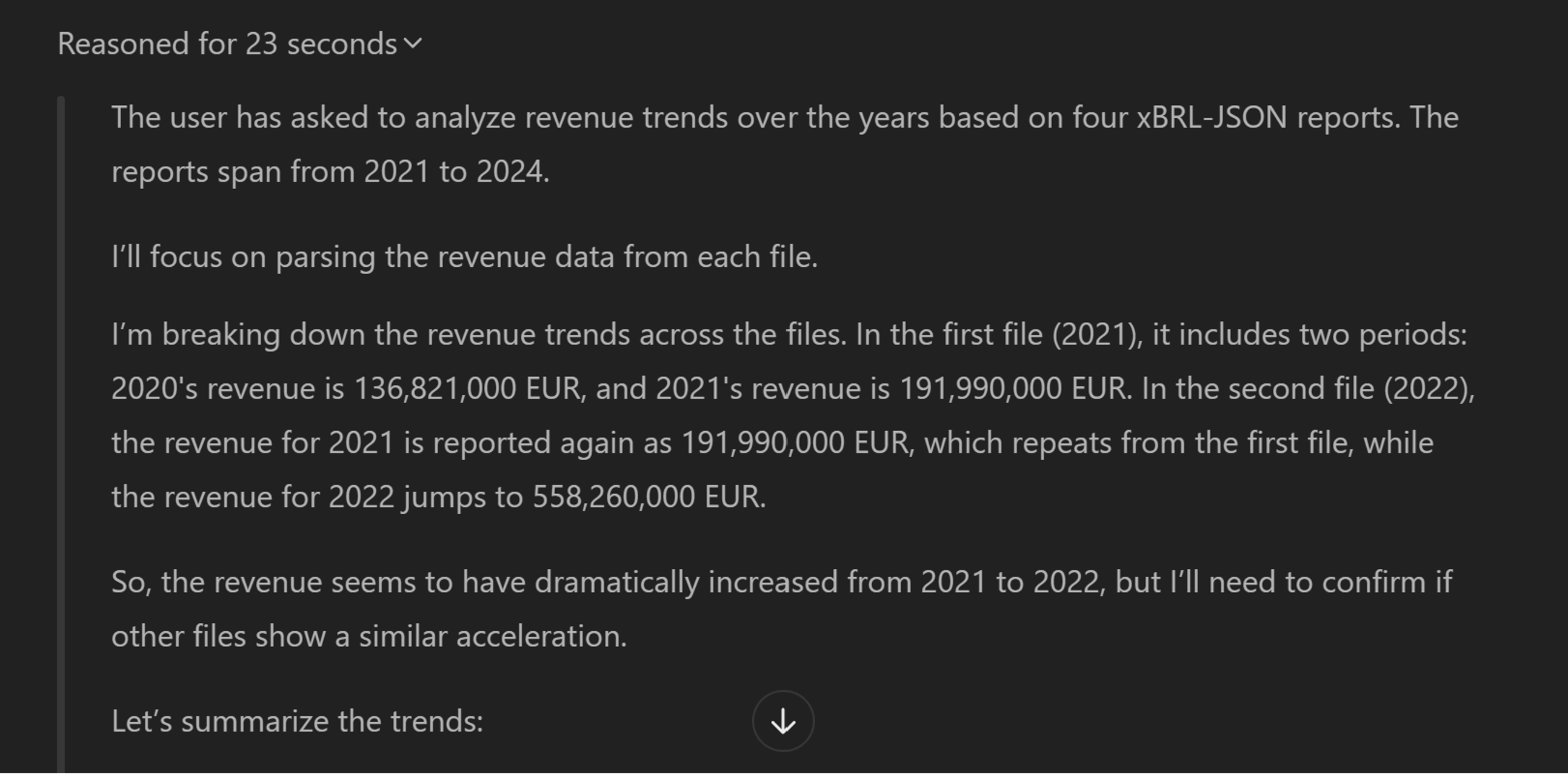

The model has made the discovery that each file contains information about two fiscal periods, with many facts reported for both the current and previous financial year. While most values are consistent across overlapping years, there is a slight discrepancy for the 2022 period. In this case, it has stated that it is using the latest, revised version of the disclosure.
Such explicit reasoning, rather like an exact chain of thought, helps us to understand LLMs’ internal mechanisms. It facilitates transparency in AI decision-making – complementing XBRL’s built-in transparency – and is an important factor for building trust.
Limitations to Be Aware Of
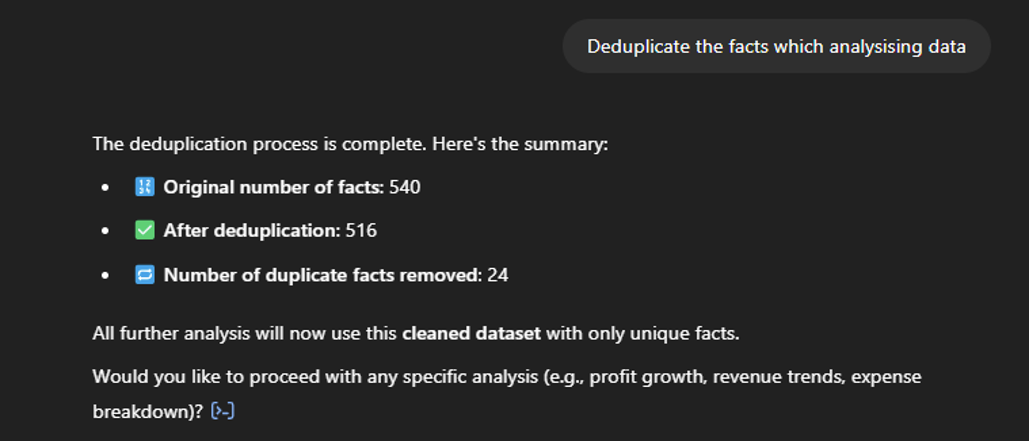
LLMs may not always provide accurate answers. It is important to review the XBRL concepts being used and to refine your prompts if any incorrect or irrelevant concepts are applied. When analysing reports across different companies, remember to explicitly mention if currencies need to be converted or standardised. Additionally, the way entities are identified in reports may not be user-friendly, so you might need to provide company names or mappings. In Inline XBRL reports, preparers may tag the same value in multiple sections to ensure consistency and support navigation. While this isn’t incorrect, deduplication is important during analysis to avoid double counting. Be sure to clearly instruct the LLM to deduplicate information where necessary, as in the example below.

Not a Production Environment Approach
Please note that the approach described in this post for analysing XBRL reports using LLMs is solely experimental and not intended for production use. In a production environment, you would need a custom-built model that fully comprehends every detail of the XBRL reports being analysed – leaving no room for assumptions – to ensure consistent and reliable results. For example, the representation of time periods may need further clarification. On a larger scale, analysing thousands of reports might require merging the xBRL-JSON data into a tabular format and integrating taxonomy information for truly meaningful insights.
Conclusions
In conclusion, this blog isn’t a definitive guide on what to analyse in an XBRL report but rather a collection of quick tips to kickstart your experiments with today’s tools. The key takeaway is that xBRL-JSON simplifies analysis by seamlessly integrating with LLMs, making it an effective way to channel XBRL reports into these analytical platforms. Enjoy exploring the fun possibilities that this approach can unlock!





