
This document is a review draft. Readers are invited to submit comments to the Best Practices Board.
Table of Contents
- 1 Introduction
- 2 Components of an XBRL report collection-processing platform
- 2.1 Receive reports
- 2.1.1 Submission format
- 2.1.2 Submission approach
- 2.1.3 Authentication
- 2.1.4 Non-repudiation by filers
- 2.1.5 Proof of filing
- 2.1.6 Resubmission of filings
- 2.1.7 Initial gateway checks
- 2.2 Process reports
- 2.2.1 Validation
- 2.2.2 Risk Assessments and monitoring checks
- 2.2.3 Workflow considerations for XBRL validation
- 2.2.4 Rendering
- 2.2.5 Publishing XBRL reports
- 2.3 Consume reports
- 2.3.1 Archival and storage
- 2.1 Receive reports
- 3 Other considerations
1 Introduction
This guide provides an overview of the common features and key considerations for designing an effective XBRL data collection and processing platform. While primarily targeted towards data collectors who are shifting from a paper-based or non-XBRL data collection process, it can also be useful for those already collecting XBRL reports.
The guide covers the three main components of a typical XBRL platform: receiving the filings, processing the data, and storing the reports. For each component, the key features, considerations, and best practices are discussed in detail.
By understanding the core functionality and design principles outlined in this document, collectors can build an XBRL collection platform that meets their specific business requirements and regulatory obligations.
2 Components of an XBRL report collection-processing platform
An XBRL collection-processing platform commonly has three main components as depicted in Figure 1
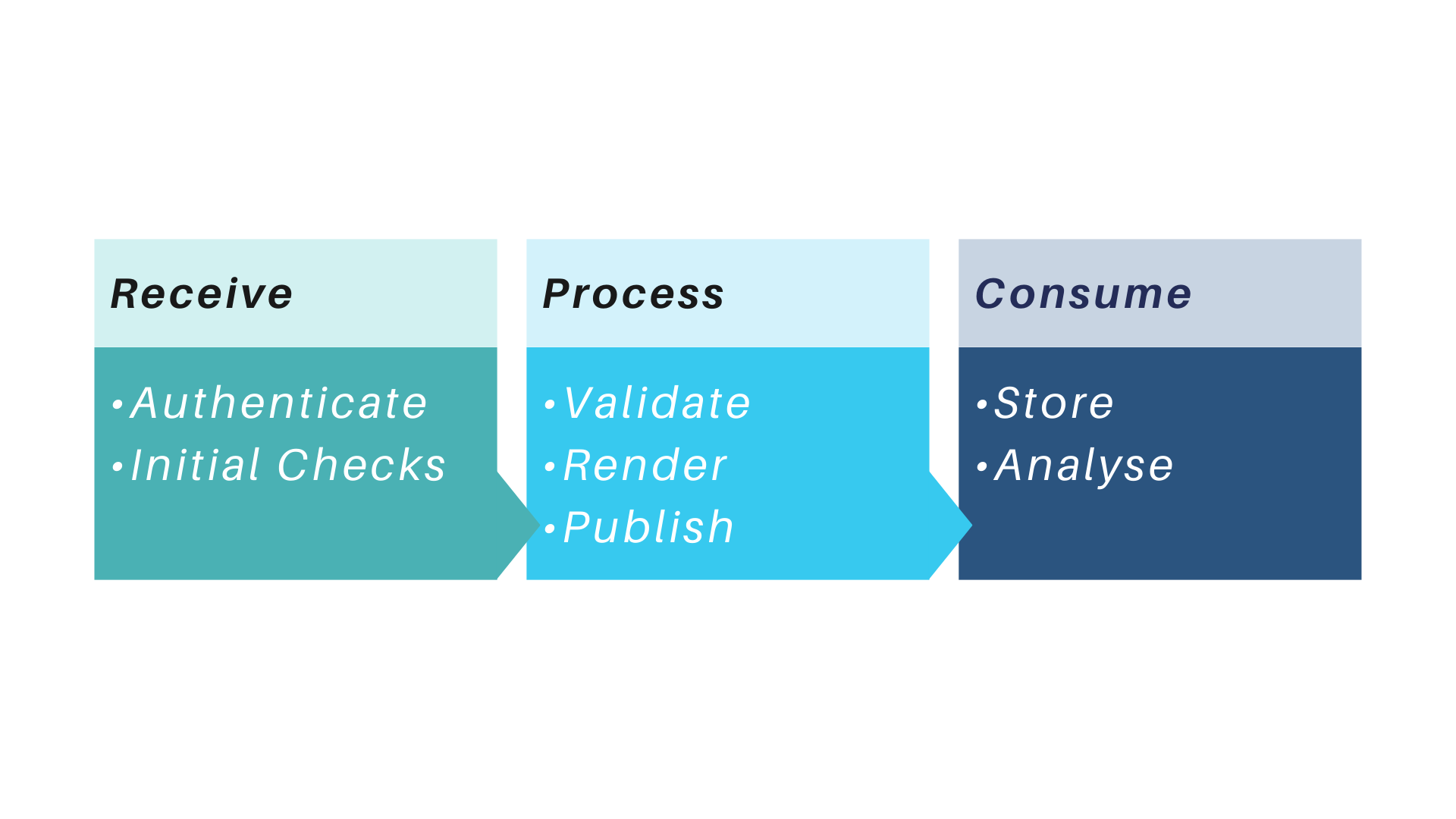 Figure 1: Components of XBRL collection-processing platform
Figure 1: Components of XBRL collection-processing platformThe platform utilises a portal or gateway to authenticate the filer, receive the filings, and perform initial checks. The next step is to process the files by performing validation, rendering and publication. The final step is to consume the processed files by storing the data in a database and analysing it.
Each of the three main components or steps of the XBRL collection-processing platform are discussed in detail in the following sections.
2.1 Receive reports
The collection platform requires a portal where the XBRL files are to be submitted. The various approaches and considerations to take into account when designing such a portal are discussed here.
While this guide focuses on XBRL reports, portals are typically designed to accept other common reporting file formats, such as PDF, XML, and CSV. This capability needs to be taken into consideration.
2.1.1 Submission format
Report Packages are the standard way of submitting and distributing XBRL reports. Report Packages allow the files that make up an XBRL report to be included into a single package file with a distinct extension that identifies its type. The files can include extension taxonomy files, image, font and stylesheet files (for Inline XBRL reports), or multiple CSV tables (for xBRL-CSV reports). Report Packages also provide a foundation for apply digital signatures to XBRL reports. Data collectors should require submission of XBRL reports using the appropriate Report Package format as this improves the user experience and ensures consistency in how reports are accessed and interacted with.
For a high-level overview of Report Packages, refer to the separate guidance document. For technical questions, consult the FAQ targeted at software developers.
- Collect XBRL reports as Report Package.
2.1.2 Submission approach
When submitting XBRL reports to the portal, two approaches are commonly used: a web portal and an API.
-
Web portal: Using a web portal provides filers with a user-interface to manually upload their XBRL reports.
-
API: An API (Application programming interface) is designed for automated computer-to-computer communication. A filing API facilitates the submission of XBRL reports directly from preparation software. Automating the submission process reduces manual effort and reduces the risk of errors.
- Evaluate the requirements for a user-friendly web portal and APIs for report submission.
- Consider implementing both approaches, as they are not mutually exclusive.
2.1.3 Authentication
XBRL collection portals need to implement an authentication mechanism to ensure that only authorised filers can submit reports to the portal. Typically, filers will need to register with the portal prior to their first submission. Authentication mechanisms are based on the collector's security policy. This typically involves a username and password combination, and may additionally include Two-Factor Authentication (2FA).
2.1.4 Non-repudiation by filers
Non-repudiation mechanisms are implemented to guarantee that the reported information cannot be denied by any involved party (sender or receiver). The benefit of this approach is that the filer can be certain that the document was submitted, and the receiver is certain that the file received is authentic.
- Digital signatures: Consider requiring digital signatures for reports. Digital signatures provide cryptographic proof that a report was submitted by a specific entity at a specific time. They guarantee the authenticity and integrity of the document, making it tamper-evident and legally binding.
2.1.5 Proof of filing
XBRL collection platforms should provide an acknowledgement to entities upon report submission along with hash totals and time stamps. It ensures a record of receipt for regulatory compliance or internal accountability.
- Audit trails: Implement audit trails track and record all actions taken within the platform, including report submissions. This comprehensive log of activities serves as evidence in case of disputes or legal proceedings, ensuring accountability and transparency.
2.1.6 Resubmission of filings
XBRL collection platforms must be able to accommodate resubmission of filings. This means that files that have previously been submitted to the platform will be re-submitted at a later time. The reasons for this range from error correction, updated information or updated regulatory requirements. Regardless of the reason, it is important that the platform ensures coherent and integral processing of files. Two approaches for retaining resubmitted reports are described below. Which of these is appropriate will depend on the receiving organisation's policies:
-
Versioning: This approach retains all historical versions of the filed reports, including the original submission and any subsequent resubmission of filings. This allows for comprehensive audit trails and historical analysis. This approach will require larger capacity for storage, since all versions of the filing are retained.
-
Latest version only: This approach maintains only the most recent version of the report, effectively replacing any previous submissions. This simplifies user navigation and ensures clarity regarding the current reported data. However, it eliminates access to historical data, potentially hindering investigations or comparisons.
- Clearly flag the latest version of the report for filers, internal supervisors, or external users. This can be achieved through visual cues, timestamps, or dedicated version labels.
- Maintain secure audit trails documenting all resubmissions. *Establish clear policies for resubmission of filings, including acceptable reasons, versioning information, and the process for accessing historical data (if applicable).
2.1.7 Initial gateway checks
The collection portal is the entry point to the processing platform. By implementing an automated gateway check at the point of file upload, the platform can preemptively address potential issues, ensuring that only suitable, secure, and processable files proceed further. This practice minimises risks and streamlines subsequent processing steps. It is good practice for collection platforms to employ an initial gateway checks for submitted files. Following are typical automated initial gateway checks:
-
Malware check: Prior to conducting any further, more involved checks, it is essential to run a malware check on the submitted files. This will ensure that the risk of allowing malware to enter the collection platform or worse, the organisation, is limited.
-
Format check: Another basic check that should be conducted is that the file format of the submitted file(s) adheres to the platform's specification. This ensures that only file types are accepted which are supported and processable by the platform.
-
Taxonomy compliance: It is possible to check whether the submitted XBRL file is based on the taxonomy version that is expected for the submitted filing period. This basic check can be used to quickly reject incorrectly filed reports and saves more comprehensive XBRL validations for correctly filed reports.
2.2 Process reports
Once the XBRL files have been received, they need to be processed. This section will detail what it entails to process XBRL files and how the platform should be designed accordingly.
2.2.1 Validation
The first step of processing XBRL reports should be data validation. This is essential to ensure only high-quality data is received and used for further analysis. Validation ensures that submitted data is technically correct and business compliant. Following are typical validation checks:
-
XBRL validation: These checks ensure conformance to the XBRL specifications. This includes basic checks for example verifying data types (ensuring numbers are entered for numeric fields) and structural checks defined within the taxonomy.
-
Business rules: These rules go beyond technical accuracy and enforce specific business domain requirements. For example, a business rule might check if a specific line item must be reported when another line item exceeds a certain threshold.
-
Filing rules: These rules ensure the data meets the technical specifications of the specific filing system where it will be submitted. These rules might involve specific tagging requirements or other technical details mandated by the filing system.
The above tests should be implemented as an automated process, to ensure that all checks can be performed in a fast and efficient manner. Read more about implementing business rules and preparing and publishing filing rules in a separate guidance.
Consider using XBRL-certified validating processors to ensure that software accurately validates reports according to the required technical specifications, facilitating seamless interoperability between different XBRL-compliant applications. This guarantees that an XBRL report created in one software can be reliably consumed by any other conformant XBRL software. Learn more about certified software on the XBRL software certification page.
2.2.2 Risk Assessments and monitoring checks
In addition to the core XBRL and business rule validations for submitted reports, many organisations implement internal scrutiny checks for risk assessment and monitoring purposes. These may include identifying trends, anomalies, unusual values or missing optional data points. These checks can be particularly valuable for identifying potential issues. Many of these validation checks can be automated by defining a private set of XBRL Formula Rules specific to the organisation's needs. This streamlines the process, reduces manual effort, and ensures consistent application of internal risk assessment criteria. Such internal monitoring checks can flag reports for further manual review.
2.2.3 Workflow considerations for XBRL validation
It is essential to view the processing platform as an ecosystem of various tools that need to work together to effectively process XBRL files. The tools and processes within this ecosystem must work hand in hand to accomplish an efficient and highly automated workflow. In following are key aspects of this workflow to consider:
-
Streamlined reporting workflow: Map out the flow of XBRL reports from the collection portal to the validation engine and back to the portal. This ensures a smooth user experience for filers and facilitates efficient communication of validation results. Consider implementing functionality within the portal to display clear and actionable feedback to users based on validation outcomes.
-
Multiple validation processors: Multiple processors may also be implemented to optimise validation processing time. Sometimes, dedicated processors are assigned to each taxonomy version to reduce the overhead of repeatedly loading taxonomies during validation. This setup enhances efficiency, allowing faster and more streamlined processing of large volumes of XBRL reports. In such cases pre-processing of XBRL reports is required to identify the correct taxonomy version and route them to the right processor.
-
Standardised APIs: Consider leveraging standardised APIs to facilitate seamless integration between the collection platform, XBRL validator, and any other relevant systems within the ecosystem. This promotes data exchange and simplifies the overall reporting process.
-
Flexible configuration: Look for validation solutions that offer flexible configuration options. This allows to tailor the validation process to specific needs and integrate it seamlessly with existing infrastructure.
Carefully evaluating these workflow considerations can ensure that XBRL validation becomes a well-integrated and efficient component of the overall platform.
- Always validate the XBRL reports to ensure that submitted data is technically correct and business compliant.
- Consider using XBRL-certified software for validation.
- Plan the workflow of XBRL reports from the reporting portal to the validation process, the communication of validation results to filers, and further downstream processing of reports.
2.2.4 Rendering
The XBRL platform should consider rendering the collected XBRL reports to users, ensuring they are accessible in a format that is easy for humans to understand. The users of the reports can be just the internal staff or broader stakeholders when reports are made publicly available.
The XBRL collection platform will need to provide a way for users to view reports. Users may be internal staff, or the public, in the case of reports that are made publicly available. The approach taken will depend on the format of the reports:
-
Inline XBRL An Inline XBRL report is an HTML document that can be viewed directly in a web browser. In order to make the XBRL data in Inline XBRL reports more readily accessible to users, collectors are recommended to make reports available in online, Inline XBRL viewer software, in addition to providing download links to the collected report package. Here is an example of an Inline XBRL report published in viewer software.
Collectors may also consider providing additional interactive functions for searching and analysing the data in Inline XBRL reports.
-
XBRL reporting templates (Table Linkbase) XBRL Reporting Templates (Table Linkbase) provide a standard way for taxonomy authors to define business-user-friendly table structures to render XBRL reports. Table linkbase is most suited for a closed reporting environment where XBRL reports can be visualised in a standard template.
When the taxonomy includes reporting templates, data collectors should use them to render XBRL reports. Compliant XBRL software can interpret these reporting templates within the taxonomy and render the XBRL reports accordingly.
To learn more about Table Linkbase, read this separate piece of guidance, which explains its features.
2.2.5 Publishing XBRL reports
Some data collectors make collected reports available to the public. Where this is done with XBRL or Inline XBRL Reports, it is important to consider the following aspects:
- Reports submitted by filers should be made available to users "as is" without any modification.
- When XBRL reports are collected as Report Packages, they should also be published in the same format to maintain consistency and ensure seamless usability across the reporting process.
- Collectors should consider enhancing report accessibility for automated tools by providing an API. By allowing software to access and interact with the XBRL data programmatically, users can automate data retrieval, analysis, and integration processes, making the data more actionable and valuable.
- xBRL-JSON provides a simple representation of XBRL data in JSON format. The format is intuitive and can be quickly understood by someone new to XBRL and easy for developers to work with. If reports are collected in a format other than xBRL-JSON, such as Inline XBRL, data collectors should consider publishing reports in xBRL-JSON in addition to the original format. Publishing data in xBRL-JSON makes the data more readily accessible and reduces the barrier to entry for consumers looking to take advantage of the collected structured data.
- Collectors can consider publishing the XBRL report rendering as discussed in Section 2.2.4.
2.3 Consume reports
This section discusses data analysis and storage considerations, particularly in the context of XBRL data. General principles of data storage management strategy apply to storing XBRL data, such as clarity on how the data will be analysed, decisions on read speeds, and decisions on BI architecture. Specific considerations for analysing and storing XBRL data are described below:
-
Guiding taxonomy modelling with analysis needs: Understanding the specific analysis requirements can help optimise taxonomy modelling. This means identifying the kinds of data and insights that are most important to stakeholders and ensuring that the taxonomy is structured in a way that facilitates easy extraction and analysis of this data.
-
Leveraging metadata in taxonomy for data analysis: The metadata associated with concepts, dimensions, and other relationships within the taxonomy provide valuable properties that can be leveraged in data analysis. This metadata can include definitions, labels, references, and other attributes that enrich the understanding and usability of the data. By incorporating these metadata elements into the data analysis model, can enhance the depth and accuracy of analysis.
-
Planning for taxonomy version changes: Data collectors should have a process for handling changes to taxonomies. This involves staying informed about taxonomy updates, understanding their impact, and implementing strategies to adjust data collection, storage, and analysis processes accordingly.
-
Involving an XBRL specialist in data handling: Having an XBRL specialist in the team responsible for parsing and storing XBRL data can provide significant benefits. An XBRL specialist brings expertise in the intricacies of XBRL, including the proper interpretation of taxonomies, handling complex data structures. Their guidance can help avoid common pitfalls and improve the overall quality and efficiency of data management processes.
2.3.1 Archival and storage
Long-term, secure storage of XBRL filings is crucial for legal and regulatory compliance. Regulatory bodies often mandate the retention of filings for a specific period, sometimes extending to several years. Additionally, XBRL data may be used for future audits or investigations, necessitating its long-term accessibility.
Here are some key considerations for XBRL archival and storage:
-
Immutability: Filings received from reporting entities should be stored in a way that guarantees immutability. This means the data cannot be altered or tampered with after submission.
-
Security: The storage solution should implement robust security measures to protect the data from unauthorised access, accidental deletion, or corruption.
-
Accessibility: While ensuring immutability, the storage solution should also allow for easy retrieval of archived data for authorized users when needed for audits, investigations, or other legitimate purposes.
-
Submission receipts: Providing the filer with a cryptographic hash of the XBRL filing upon receipt allows the filer to verify that the filing has not been modified in anyway during storage or retrieval.
-
Digital seals: Applying a digital signature to a submission receipt provides an additional layer of tamper-evident protection, by giving the filer a non-repudiable record of the receipt of the filing.
-
Leverage taxonomy metadata for data analysis
-
Plan for XBRL report store and archival considering security and accessibility
3 Other considerations
This section discusses other considerations while setting up the XBRL collection-processing platform. These aspects need consideration to ensure the platform is scalable and supports different user requirements.
-
Design to handle multiple taxonomy versions: Implement the collection-processing platform architecture so that it can support various taxonomy versions. Collection-processing platforms might also require supporting multiple versions of the same taxonomy simultaneously, based on applicability dates. Provide a mechanism for seamless updates and integration of new taxonomy versions.
-
Scalability to include more reports (Entry points): Design the collection-processing platform to be modular, allowing easy addition of new reports (taxonomy entry points). Anticipate future reporting needs based on industry trends and regulatory changes. For example, the taxonomy may expand to include entry points specific to 'Small and midsize enterprises'.
-
Infrastructure scaling: Ensure the infrastructure can handle high volumes of reports, especially during peak reporting periods. Develop contingency plans for handling data spikes, such as scaling resources or prioritising critical tasks.
-
Need for test environment: Consider establishing a dedicated test environment that replicates the live collection-processing platform. The test environment allows preparers and software vendors to test filings, ensuring their reports comply with the platform's requirements. Implement the same validation checks and rendering mechanisms as the live environment to ensure consistency. Set policies for disposing of test submissions to maintain a clean test environment.
-
User support: Establish a dedicated help desk to assist users with platform-related queries and issues. Develop a knowledge base, including FAQs, troubleshooting guides, and best practices for report preparation. Develop a comprehensive help manual that guides users through the entire reporting process.
-
Documentation: Maintain an up-to-date list of all taxonomy versions supported by the platform. Offer a detailed and accessible list of all validation rules applied during the report submission process. Include a section on common validation errors, their causes, and steps for resolution. Consider providing a user-friendly taxonomy viewer to help users understand and navigate different taxonomies.
This document was produced by the Best Practices Board.
Published on 2024-12-17.




