
Narrative disclosure analysis with GPT-4

New technologies such as machine learning and generative AI are creating exciting new opportunities for understanding business performance. In particular, they can crack open relatively intractable data that is difficult to analyse conventionally, making it easier to access new insights without deep technical knowledge.
In my last blog post I began to explore how GPT-4 can understand XBRL data and can be leveraged to do fundamental analysis using simple English queries. In this post, I will delve into what GPT-4 can do specifically with narrative data, aka text blocks. Sustainability disclosures in particular are rich in narrative and require new analytic approaches to effectively process this text-based information.
Unlike quantitative data, which includes numbers and statistics, narrative disclosures offer a detailed explanation and context around a company’s performance, risks, and prospects. However, it is more difficult to compare and spot patterns in large amounts of narrative data.
Historically, analysts – and available software tools – have primarily focussed on the insights we can draw from the numerical data in corporate reports. With the rise of text analytics models, we can now also better analyse narrative disclosures, and make better use of this valuable resource. Using text analytics does, however, typically involve writing code, using relevant libraries and interpreting the results, all of which requires a certain level of technical expertise.
This blog post explores how narrative disclosure can be easily analysed in GPT-4 using natural language and without necessarily knowing coding techniques.
Accounting policy analysis
Let’s start with a simple accounting policy text analysis for two sample companies. Accounting policies tend to remain unchanged from year to year. However, where there are changes it is useful to be able to pinpoint them, to permit further investigation if necessary. Let’s see how GPT-4 can assist in spotting such changes.
Here I supplied GPT-4 with the necessary data by uploading two ESEF reports for the same company in xBRL-JSON format for consecutive years. In my query I listed the relevant accounting policy concepts and asked GPT-4 to identify any text changes between the two reports.
Here GPT-4 reads the report, recognises that there are HTML tags in the text block content, and removes them for clarity, which is impressive.
Given the ongoing discussions around retaining text-block formatting tags for readability, this is a gentle reminder that HTML styling is typically discarded during automated text analysis.
For the first company (Nestlé Holdings, Inc.), GPT-4 recognised no significant change in the accounting policy text.

NESTLE HOLDINGS, INC.
Source Report: https://filings.xbrl.org/entity/549300EAEU8YV8MQXP30
For the second company (ASCENTIAL PLC), GPT-4 identified two changes: a minor modification in the goodwill accounting policy and a new disclosure, likely to be of most interest, related to the accounting policy for environmental expenses.

ASCENTIAL PLC
Source Report: https://filings.xbrl.org/entity/213800VDXQDA7KD2IQ21
These insights are valuable, and what’s even better is that they can be obtained without writing any text analytics code. Simple experiments like this demonstrate how these AI techniques make analysis much easier.
Going concern disclosures
In this example, we will look at going concern disclosures across companies. Let’s say you’re doing a thematic analysis on a large number of company disclosures. The first step is to get a handle on these disclosures, capturing the wide variation across the text in a meaningful and useful way.
One common metric used to understand text data is the TF-IDF score, which stands for Term Frequency-Inverse Document Frequency. TF-IDF provides a combined numeric score based on the number of words, the frequency of words and how rare the words are within the sample set of documents.
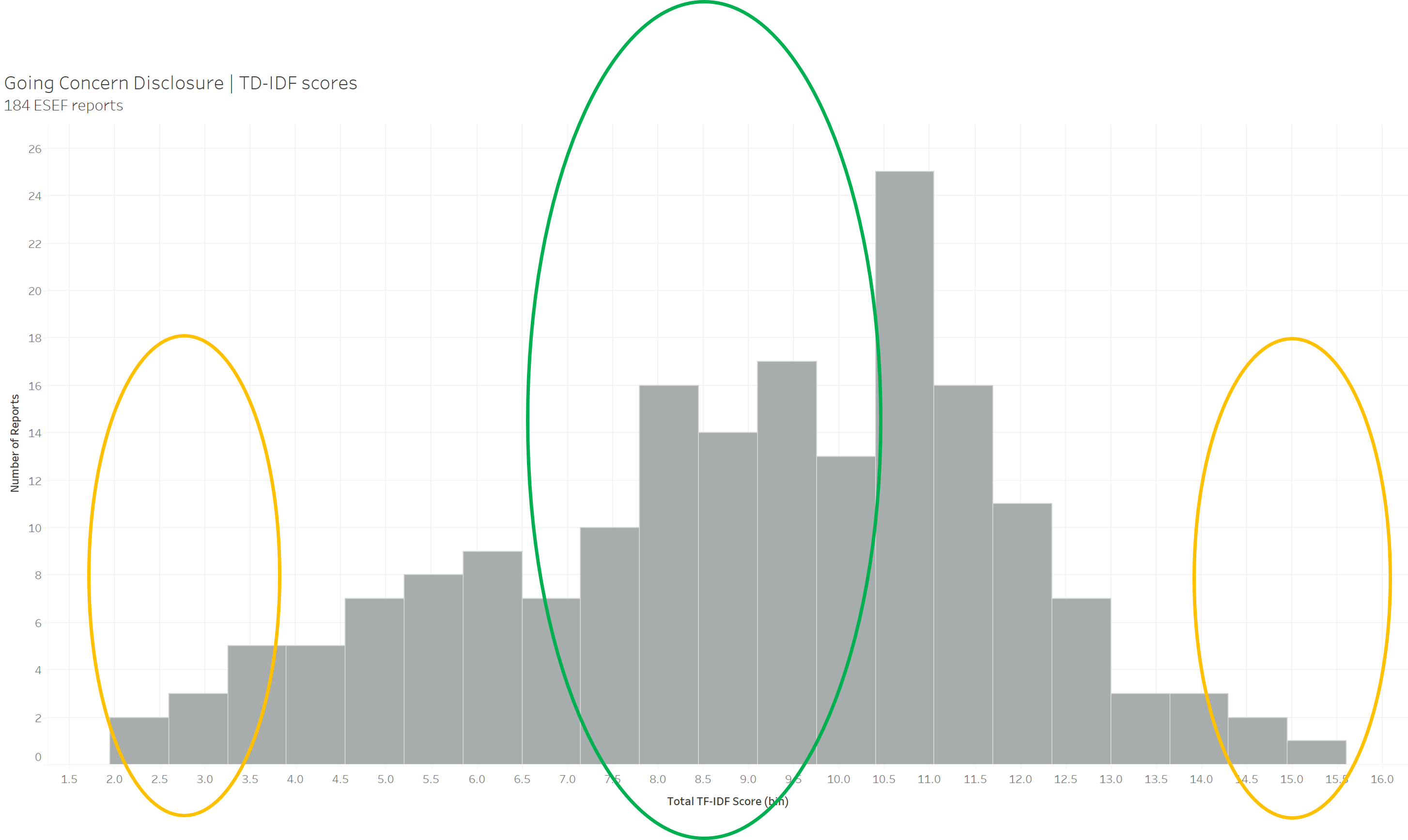
Here I provided GPT-4 with going concern disclosures from 180 European Single Electronic Format (ESEF) reports and asked GPT-4 to calculate the TF-IDF scores. Normally, the process of calculating TD-IDF scores would involve the use of Python, R or some other statistical language and a range of specialist coding skills.

Here is the statistical summary of the TF-IDF score it calculated.

The mean score is 8.99 with a standard deviation of 2.7. This means a typical going concern text in the sample has a TF-IDF score of around 9. By plotting a histogram, we can see that some companies have unusually high scores while others have very low scores, both of which might be interesting to investigate further. A very high TF-IDF score indicates the use of more words and more unique words.
Let’s understand and interpret these scores with examples. Here is a going concern disclosure with a TF-IDF score of 8.9, very close to the mean, representing a typical disclosure within the sample. It looks like a standard going concern disclosure with nothing particularly striking to note.

BAKKAVOR GROUP PLC
Source Report: https://filings.xbrl.org/213800COL7AD54YU9949/2023-12-30/ESEF/GB/0/213800COL7AD54YU9949-2023-12-30/reports/ixbrlviewer.html
Let’s compare this with a disclosure with a much higher TF-IDF score, of 14.6.

VICTREX PLC
Source Report: https://filings.xbrl.org/213800UYNPHAUNHPXL67/2023-09-30/ESEF/GB/0/213800UYNPHAUNHPXL67-2023-09-30/reports/ixbrlviewer.html
This disclosure is visibly longer than a standard going concern disclosure. It contains notable phrases such as “volume dropped by 24%,” “lower demand,” and “no signs of recovery.” For anyone conducting a thematic analysis on going concern disclosures, this report stands out as a candidate for further investigation. The financial statement shows a dip in revenues, profit, and cash from operating activities, which explains the length and detail of this going concern disclosure, and indicates potential risks of interest to analysts.
In this example, we saw how applying a relatively complex statistical measure can allow us to detect unusual disclosures and provide useful insights. All of this was done with simple English queries using GPT-4, making the analysis much easier and bypassing the need for detailed statistics and coding knowledge.
Sustainability disclosures
Sustainability mandates are being rolled-out worldwide. Sustainability reports tend to be rich in narrative, offering both fertile ground and a strong incentive for analytical innovation to make the most of this huge new supply of information.
One of the challenges around sustainability disclosures is the potential for greenwashing by companies. In this example, we will see if GPT-4 can detect hints of greenwashing, using data from Indian sustainability reports. India’s Business Responsibility and Sustainability Reporting (BRSR) mandate introduced a wide range of sustainability disclosures for the top 1,000 listed companies from 2023, with phased-in assurance starting in 2024. The data collection is in XBRL format along with PDF.
I have used the disclosure example “Approach to Adapt or Mitigate Risk Identified,” which requires companies to report their adaptation or mitigation plans for identified risks. The disclosures are expected to be objective and specific about these plans.
Here I asked GPT-4 to analyse for objectivity, using plain language and without specifying how that should be defined.

GPT-4 described its approach to determining objectivity, which includes looking for specific timelines, actions, qualifiers, and measurable outcomes.

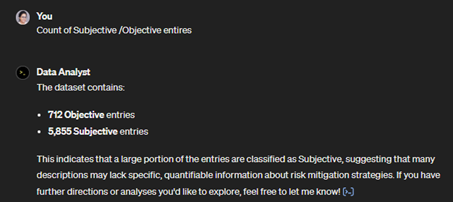
GPT-4 then classified each entry for objectivity based on these criteria, analysing 6,500+ disclosures across 1,000 reports. Across the sample it classified the majority of disclosures as subjective, as shown in the summary below.
Let’s look at a few examples to understand objective and subjective classification by the model.
Subjective disclosures (with my own emphasis in bold):
- Address and manage crises in both tangible and intangible ways that we believe will mitigate impacts effectively
- We believe in ensuring that our workplaces are safe, healthy, and conducive to high productivity.
- The Company stays up to date with the latest developments in the industry to ensure best practices.
- Reducing the energy intensity through various measures to achieve long-term sustainability goals.
Objective disclosures:
- Continually invest in employee capability through mandatory training programs, with a minimum of 40 hours of training per employee per year, to enhance operational efficiency and safety.
- We have set up a year-on-year target of 5% for reduction in energy consumption, enforce these targets through regular…
- We have made an agreement for 13.20 MW to source renewable energy, which contributes to our sustainability goals.
- All related party transactions are approved by the Board of Directors to ensure transparency and accountability.
Decision-useful answers from simple questions
The advent of Large Language Models (LLMs) offers a transformative addition to conventional analysis techniques. By integrating LLMs with traditional data analysis, we open new horizons for exploring data beyond predefined dashboards and static views. One of the most compelling advantages of LLMs is their ability to process queries in plain language. This feature significantly reduces the need for extensive training in statistics and machine learning. Analysts and stakeholders can now interact with data intuitively, asking complex questions without needing to translate them into specialised syntax or code.
Clean, structured data is vital for ensuring the accuracy and reliability of the insights generated by both traditional methods and LLM-powered analysis. The analyses presented in this post used either original XBRL reports converted into xBRL-JSON format or extracts from xBRL-JSON reports. GPT-4 understands xBRL-JSON better than unstructured data extracted from PDF, which makes the analysis more reliable and leads to more valuable insights.
We are only at the beginning of understanding what LLMs can do, and this blog comes with a few caveats. We would remind users to be aware of the possibility of AI hallucination, and to confirm notable results using the original source data (a task made much easier using structured, traceable digital disclosures!). The examples presented here are experimental and not part of an academic study. They were based on English language disclosures only, and GPT-4 was not exposed to the underlying taxonomy. But while the approach is not perfect, the results were too powerful to ignore.
Do you feel inspired and want to experiment? Start with one xBRL-JSON report in GPT and ask questions. I’m sure it will be fun!




